Harnessing Elastic APIs for custom AI-driven SOAR


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
Security teams face a daunting mix of relentless alerts, complex investigations, and limited resources. It’s not just about detecting threats; it's also about responding quickly and efficiently. Elastic Security has long provided prebuilt capabilities for detection, investigation, and response. But what really sets Elastic apart is its open, API-first approach that gives you the power to build and automate specific workflows at your security operations center (SOC).
In this blog, we’ll demonstrate how Elastic’s extensible APIs unlock new possibilities for AI-driven security orchestration, automation, and response (SOAR) using a common “for-instance.” You’ll learn how you can design, automate, and continuously refine your own response playbooks by combining Elastic’s security platform with AI and collaboration tools like Slack.
Enhance your workflow with Elastic APIs
In this scenario, an SOC detection engineering team is facing a familiar challenge: missing key service level objectives for critical alerts. Despite having strong tools in place to improve mean time to respond (MTTR), the team is still struggling to keep up with the volume and urgency of alerts. As a result, some critical alerts are occasionally triaged too late or not resolved within expected timelines. To address this, the team looks to further enhance their workflow with automation, AI, and Elastic’s powerful APIs.
Now, imagine a workflow where a critical alert is detected, triaged, and responded to consistently with analysts empowered to guide and oversee every step. Here’s how this solution comes together using Elastic’s flexible APIs and a common collaboration tool like Slack.
Let’s break down the steps of this project.
Monitor an Elastic cluster using the Elasticsearch Python client.
Watch for any alert marked as critical.
Send the alert JSON to the Elastic AI Assistant for Security via its API.
Retrieve the AI response.
Post the AI response into a Slack channel.
Tag the relevant security analyst in the Slack message to notify them and enable direct action within Slack.
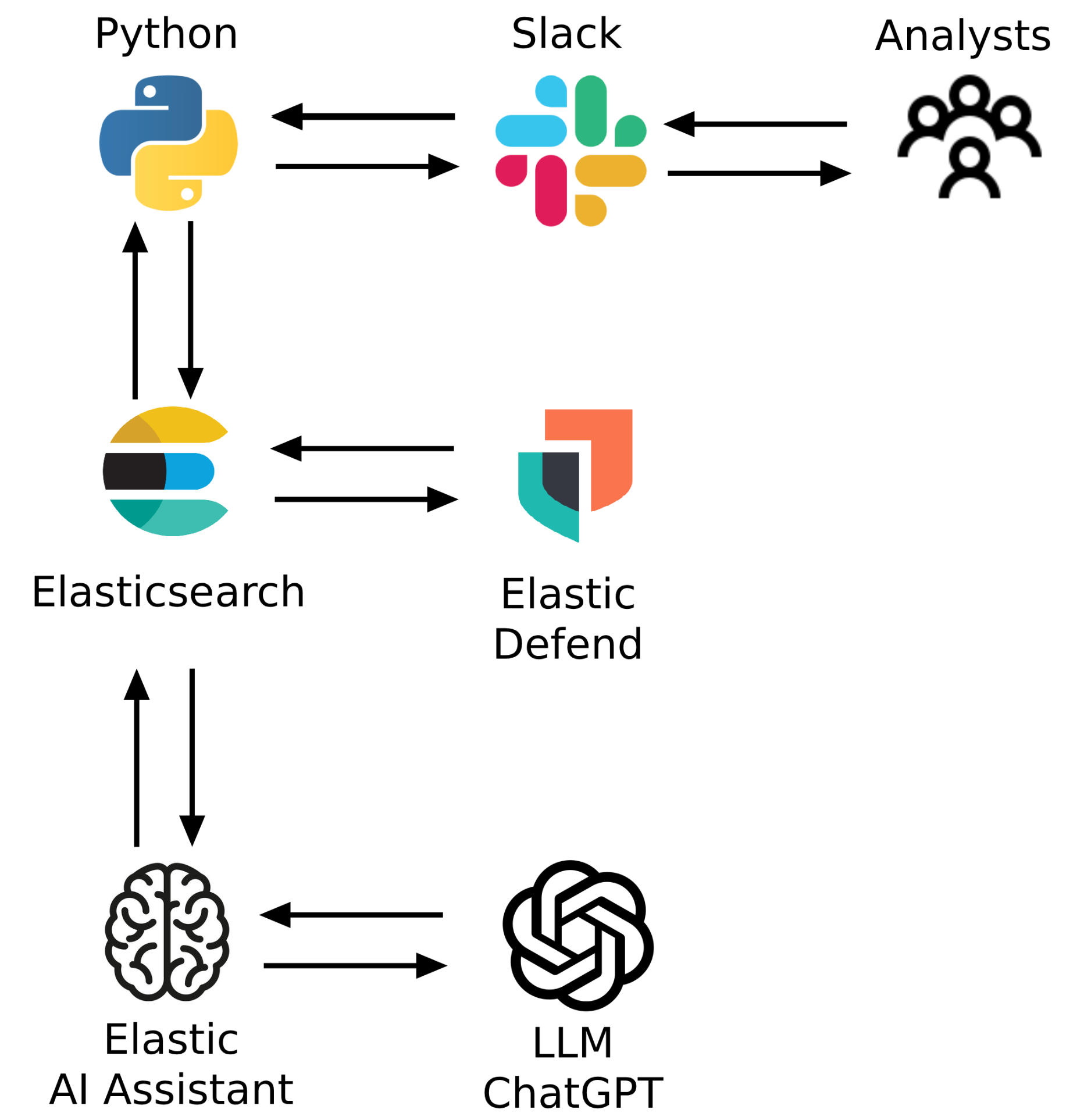
Timeline of events
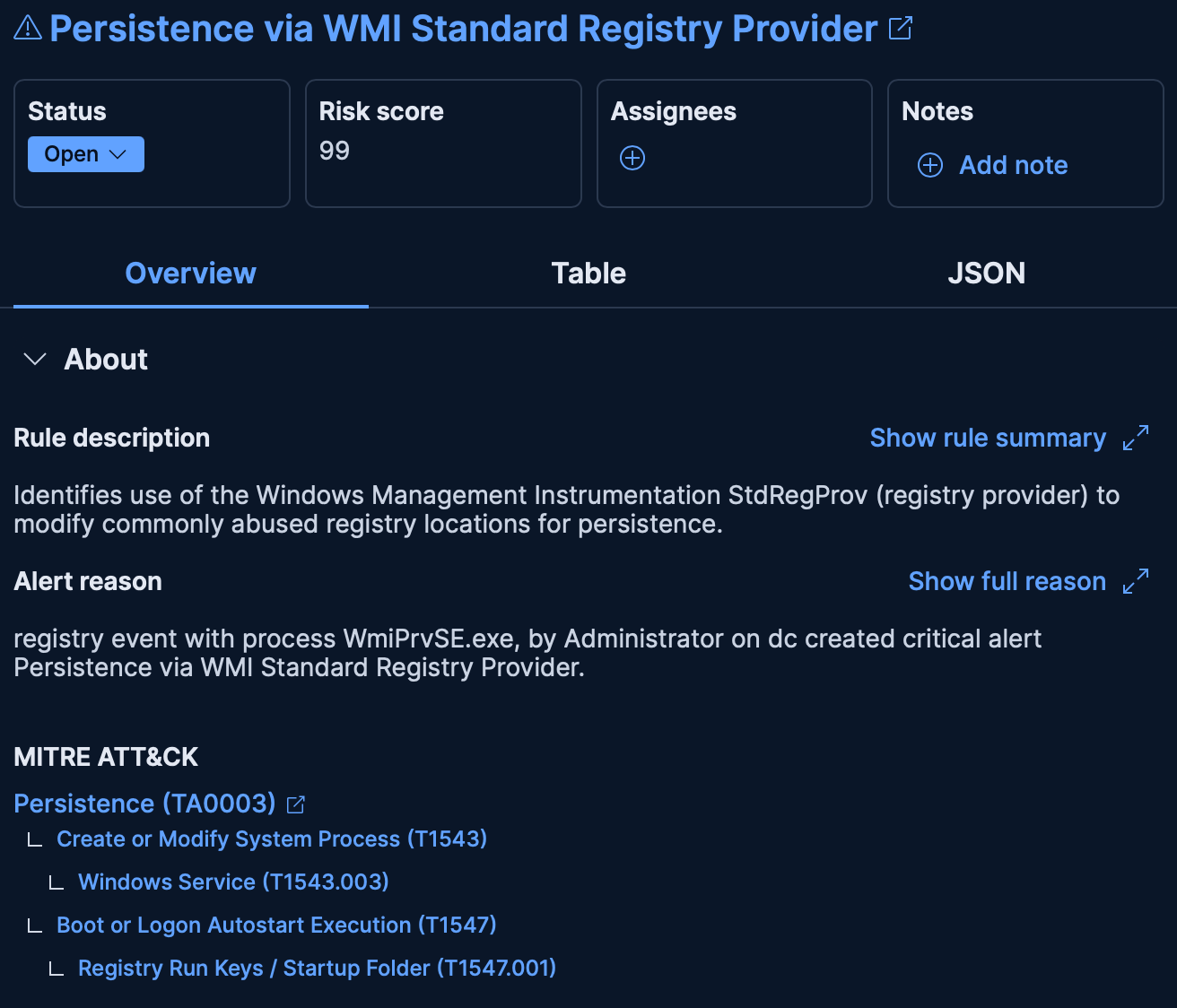
Let’s walk through a timeline of events. First, Elastic Security receives a critical alert for an essential Windows server protected by endpoint detection and response, Elastic Defend. In this case, Elastic detected that Windows Management Instrumentation (WMI) was used to create a registry key, enabling persistent access to this critical server.
Elastic Security alert:
Python can be used to query Elastic every minute for any critical alerts. When such an alert is discovered, the full JSON payload of the alert is extracted for processing. Below is an example Python that can be used to monitor Elastic for critical alerts in real time:
es = Elasticsearch(
os.getenv("ELASTICSEARCH_URL"),
api_key=ELASTICSEARCH_API_KEY
)
def monitor_alerts():
from datetime import datetime, timedelta, timezone
import time
polling_interval = 60 # Poll every 60 seconds
index_patterns = {
"endpoint": {
"pattern": ".ds-logs-endpoint.alerts*",
"timestamp_field": "Responses.@timestamp"
},
"security": {
"pattern": ".internal.alerts-security.alerts-default-*",
"timestamp_field": "@timestamp"
}
}
last_timestamps = {
key: datetime.now(timezone.utc).isoformat().replace("+00:00", "Z")
for key in index_patterns
}
while True:
for key, config in index_patterns.items():
pattern = config["pattern"]
ts_field = config["timestamp_field"]
query = {
"query": {
"bool": {
"filter": [
{"range": {ts_field: {"gt": last_timestamps[key]}}},
{"term": {"kibana.alert.severity": "critical"}}
]
}
},
"sort": [{ts_field: {"order": "asc"}}]
}
try:
response = es.search(index=pattern, body=query)
alerts = response['hits']['hits']
if alerts:
print(f"Found {len(alerts)} critical alert(s) for {key} since {last_timestamps[key]}")
max_ts = last_timestamps[key]
for alert in alerts:
alert_id = alert.get('_id')
if alert_id in processed_alert_ids:
continue
processed_alert_ids.add(alert_id)
alert_json = alert['_source']
process_alert(alert_json)
alert_ts = get_custom_alert_timestamp(alert_json, ts_field)
if alert_ts and alert_ts > max_ts:
max_ts = alert_ts
dt = datetime.fromisoformat(max_ts.replace("Z", "+00:00"))
dt += timedelta(seconds=1)
last_timestamps[key] = dt.isoformat().replace("+00:00", "Z")
except Exception as e:
print(f"Error fetching critical alerts for {key}: {str(e)}")
time.sleep(polling_interval)The captured JSON is then sent to the Elastic AI Assistant for Security via an API request. A prompt is appended to the JSON, providing the AI Assistant with the necessary context to generate an appropriate response.
Python prompt code:
def process_alert(alert_json):
alert_str = json.dumps(alert_json, indent=2)
prompt = (
f"Please look at this JSON:\n{alert_str}\n\n"
"You are a security analyst and you want to run commands to start a forensic investigation for this alert. "
"Make sure you summarize the alert in one paragraph. "
"Summarize the alert and then give 5 commands that you would run to start your IR investigation. "
"The next 3 commands should be dedicated to commands that would remediate the malware or malicious activity. "
"The total commands should be 8. Make sure you include the affected host via the IP address in the alert summary. "
"The commands should be in a list format and clearly separated into Investigation Commands and Remediation Commands. For example: \n"
"Investigation Commands:\n1. command\n2. command\n... \nRemediation Commands:\n1. command\n2. command\n..."
) print("Alert Received")
response = chat_complete(prompt)
print("AI Responded")Python API call:
def chat_complete(question, thread_ts=None, use_existing_conversation=False):
url = f"{KIBANA_URL}/api/security_ai_assistant/chat/complete"
headers = {
"kbn-xsrf": "true",
"Content-Type": "application/json",
}
payload = {
"messages": [{"role": "user", "content": question}],
"connectorId": CONNECTOR_ID,
"persist": True
}
if use_existing_conversation and thread_ts and thread_ts in conversation_map:
payload["conversationId"] = conversation_map[thread_ts]
response = requests.post(
url,
auth=(USERNAME, PASSWORD),
headers=headers,
json=payload,
stream=True
)
response.raise_for_status()
full_response = ""
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
try:
event = json.loads(decoded_line)
if "data" in event:
full_response += event["data"]
if "conversationId" in event and thread_ts:
conversation_map[thread_ts] = event["conversationId"]
except json.JSONDecodeError:
continue
return full_response.strip()The AI Assistant receives the API request and uses a large language model (LLM) to generate a response. This response includes an actionable summary of the alert along with recommended investigation and remediation commands.
The AI Assistant can also determine which analyst should be tagged in the Slack message. It does this by querying a custom knowledge base that contains information about the analysts working in the SOC. This custom knowledge capability is incredibly powerful and significantly enhances the AI Assistant’s effectiveness.
By centralizing institutional knowledge in a custom knowledge base, the AI Assistant minimizes delays in accessing key information. This improves the speed and consistency of operational workflows across the SOC.
Learn more about setting up a custom AI Assistant knowledge base.
Once the AI Assistant returns its response, Python is used to post the message along with the appropriate analyst mention to a specific Slack channel.
Sending the response to Slack:
response = chat_complete(prompt)
print("AI Responded")
if response:
clean_response = response.replace("**", "")
inv_match = re.search(r"(?i)\s*Investigation Commands:\s*", clean_response)
rem_match = re.search(r"(?i)\s*Remediation Commands:\s*", clean_response)
if not inv_match or not rem_match:
print("Could not find both 'Investigation Commands:' and 'Remediation Commands:' in the response.")
return
summary = clean_response[:inv_match.start()].strip()
inv_commands_part = clean_response[inv_match.end():rem_match.start()].strip()
rem_commands_part = clean_response[rem_match.end():].strip()
inv_commands = re.findall(r"^\s*\d+\.\s+(.+)$", inv_commands_part, re.MULTILINE)
rem_commands = re.findall(r"^\s*\d+\.\s+(.+)$", rem_commands_part, re.MULTILINE)
# Extract the handler from AI (e.g., "Who handles critical windows alerts?")
handler_question = f"Who handles {operating_system.lower()} alerts? Respond with just their name."
handler_response = chat_complete(handler_question).strip()
handler_id = get_user_id_by_name(handler_response)
handler_mention = f"<@{handler_id}>" if handler_id else handler_response
full_message = (
f"New Alert Detected\n\n{clean_response}\n\n"
f"Alert assigned to:\n{handler_mention}\n\n"
"Do you want me to run the investigation and remediation commands?"
)
blocks = [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": full_message
}
},
{
"type": "actions",
"elements": [
{
"type": "button",
"text": {"type": "plain_text", "text": "Yes"},
"action_id": "run_commands",
"value": "run"
},
{
"type": "button",
"text": {"type": "plain_text", "text": "No"},
"action_id": "do_not_run",
"value": "do_not_run"
}
]
}
]
result = app.client.chat_postMessage(
channel=ALERT_CHANNEL,
blocks=blocks,
text="New Alert Detected"
)
alert_data_map[result['ts']] = {
"alert_json": alert_json,
"investigation_commands": inv_commands,
"remediation_commands": rem_commands,
"host_ip": host_ip,
"ai_summary": summary
}Slack message:
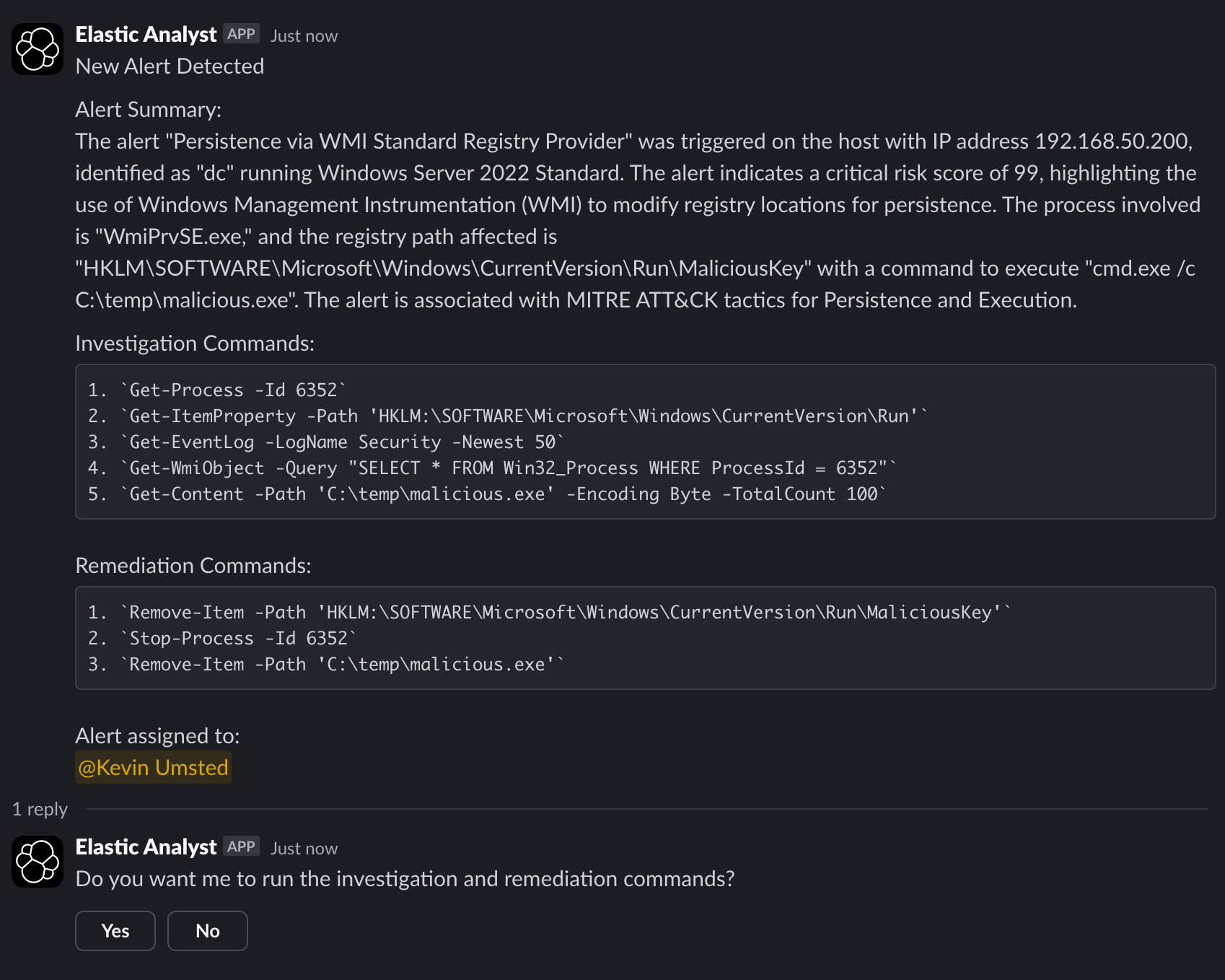
At this stage, a Slack message is generated containing a meaningful summary of the alert, the affected host, and a list of suggested investigation and remediation commands. The analyst assigned to the alert is @mentioned in the message and presented with a Yes/No option to approve execution of the commands on the host.
In this scenario, the analyst clicks “Yes” and approves the automated response.
To execute the commands, Python and Windows Remote Management (WinRM) are used. The IP address of the affected host and the list of commands are extracted from the AI Assistant’s response and executed sequentially on the target machine.
Python command execution:
import winrm
def execute_winrm_command(host_ip: str, command: str, winrm_domain: str, winrm_username: str, winrm_password: str) -> str:
session = winrm.Session(
host_ip,
auth=(f"{winrm_domain}\\{winrm_username}", winrm_password),
transport='ntlm'
)
full_cmd = (
"$ProgressPreference = 'SilentlyContinue'; "
"$VerbosePreference = 'SilentlyContinue'; "
"$WarningPreference = 'SilentlyContinue'; "
f"try {{ {command} | Format-List | Out-String -Width 120 }} "
"catch {{ 'Error: ' + $_.Exception.Message }}"
)
result = session.run_ps(full_cmd)
output = result.std_out.decode('utf-8', errors='ignore').strip()
return output if output else "No output returned."
def execute_winrm_commands(host_ip: str, commands: list, winrm_domain: str, winrm_username: str, winrm_password: str) -> dict:
outputs = {}
session = winrm.Session(
host_ip,
auth=(f"{winrm_domain}\\{winrm_username}", winrm_password),
transport='ntlm'
)
for command in commands:
full_cmd = (
"$ProgressPreference = 'SilentlyContinue'; "
"$VerbosePreference = 'SilentlyContinue'; "
"$WarningPreference = 'SilentlyContinue'; "
f"try {{ {command} | Format-List | Out-String -Width 120 }} "
"catch {{ 'Error: ' + $_.Exception.Message }}"
)
result = session.run_ps(full_cmd)
output = result.std_out.decode('utf-8', errors='ignore').strip()
outputs[command] = output if output else "No output returned."
return outputsAnalyst executed commands:

Every action is fully tracked and auditable. The application creates a new case in Elastic Security for each incident and attaches all AI summaries, any commands run, and any outputs generated during the response, ensuring that all evidence is captured for future reference or compliance needs.
Python case creation:
def create_case(alert_json, command_output, ai_summary):
description = ai_summary + "\n\n"
if command_output:
description += "Commands Executed:\n\n"
for cmd, output in command_output.items():
truncated_output = output[:500] + "..." if len(output) > 500 else output
description += f"Command: `{cmd}`\n\nOutput:\n```\n{truncated_output}\n```\n\n"
if len(description) > 30000:
description = description[:29997] + "..."
title = "Investigation for Alert"
case_payload = {
"title": title,
"description": description,
"tags": ["auto-generated", "investigation"],
"connector": {"id": "none", "name": "none", "type": ".none", "fields": None},
"owner": "securitySolution",
"settings": {"syncAlerts": True},
"severity": "medium"
}
url = f"{KIBANA_URL}/api/cases"
headers = {"kbn-xsrf": "true", "Content-Type": "application/json"}
try:
response = requests.post(
url,
auth=(USERNAME, PASSWORD),
headers=headers,
json=case_payload
)
if response.status_code == 200:
case_id = response.json().get('id')
print(f"Successfully created case: {case_id}")
return case_id
else:
print(f"Failed to create case: {response.status_code} - {response.text}")
return None
except requests.RequestException as e:
print(f"Request failed: {str(e)}")
return NoneKibana security case:
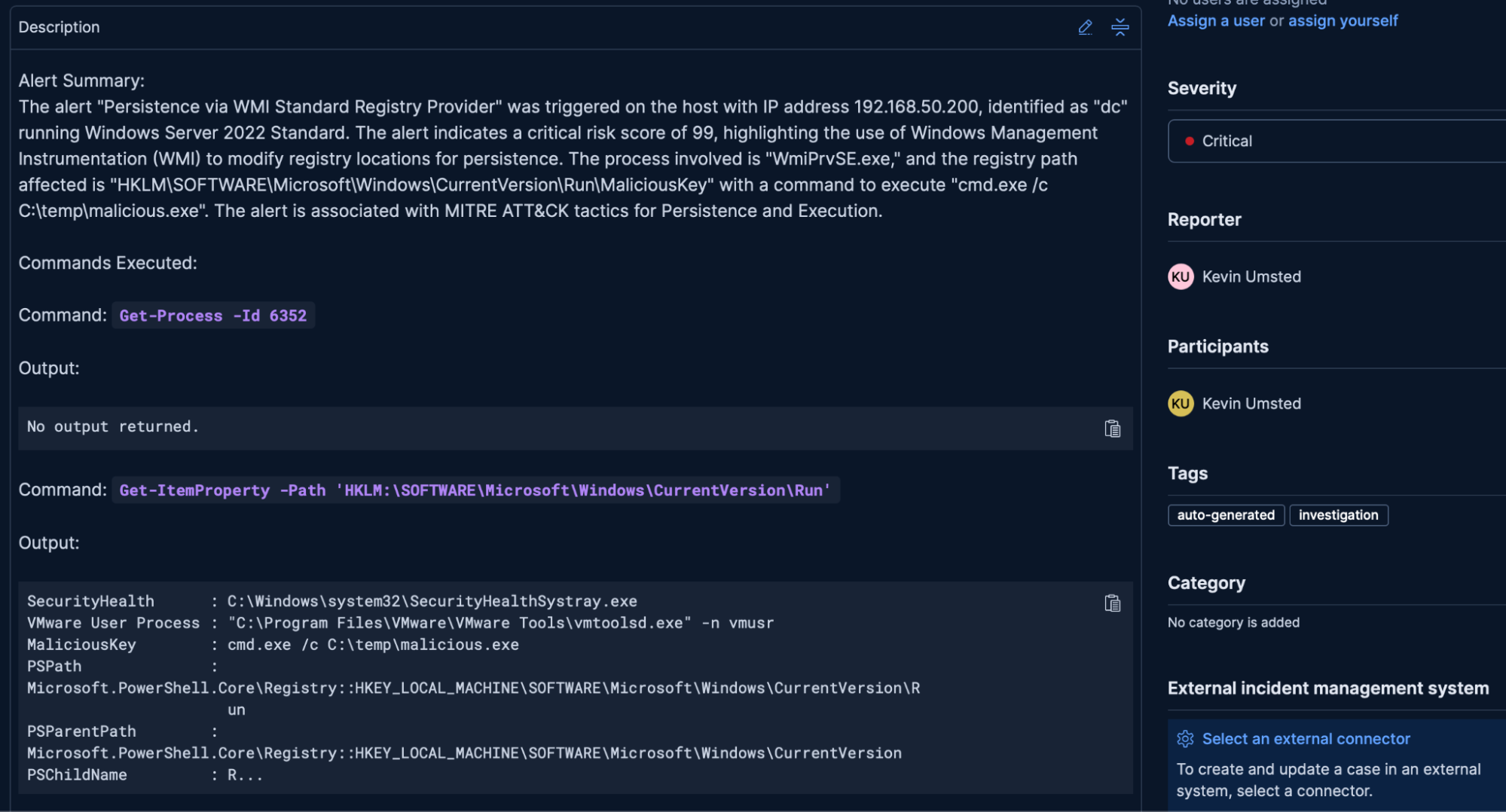
Elastic offers unmatched flexibility
Elastic Security can go far beyond out-of-the-box detection and response, enabling custom automation pipelines that integrate seamlessly with enterprise AI and collaboration tools like Slack.
Using Elastic’s powerful APIs and open source foundation, we were able to:
Programmatically monitor for critical alerts
Use the Elastic AI Assistant for Security to generate context-rich, actionable responses
Automate triage and remediation in a controlled, auditable way
Integrate directly into collaboration tools that our analysts use every day
Elastic’s open, API-first architecture gives security teams an unmatched level of flexibility to build the workflows that work best for them.This is the power of building on Elastic. Whether you’re scaling response efforts with AI, customizing alert workflows, or embedding Elastic into your existing SecOps stack, the platform is designed to work the way you need it to.

Ready to build your own?
Start building your workflows using the Elastic AI Assistant API documentation, or reach out for a deeper dive on how Elastic’s open platform can fit your unique SOC requirements.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos, or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print