Elastic’s capabilities in the world of Zero Trust operations


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
A new security paradigm
The need for Zero Trust
Zero Trust (ZT) has become one of those omnipresent buzzwords we see everywhere in the information technology (IT) ecosystem lately. The basic idea of Zero Trust has actually been around for a long time (the phrase was originally coined in 1994!1), but the practical application of Zero Trust as a real security paradigm is somewhat new and still being formulated. What Zero Trust represents is a hard shift from traditional perimeter-based and defense-in-depth approaches where multiple layers of boundary security are used to protect the resources within. The move towards Zero Trust Architectures was necessitated by the proliferation and growing complexities of interconnected cloud, edge, hybrid and services-based architectures — there is no longer a solid outer perimeter that can be defended.
Over the years, we’ve learned (often the hard way) that the main problem with relying solely on perimeter-based security is the assumption that perimeter access also conveys permissions to the resources inside that boundary. That’s a bad assumption because it’s between those layers where the enemy thrives. Once a bad actor has gained a foothold inside one of those perimeters, they can “live off the land” and hide inside until they find a path to their next target; it’s usually just a matter of time until they are able to exploit the resources within.
The distillation of Zero Trust is to never trust, always verify. This core tenet takes away that faulty assumption of perimeter-based defense and instead says that no transaction should be implicitly trusted. There are a lot of implications packed into that simple credo, and those implications start with a fundamental set of principles:
Assume breach: Organizations operate as if a breach has already occurred, designing security controls to minimize potential damage.
Identity-centric security: Identity becomes the primary security perimeter, replacing traditional network boundaries.
Microsegmentation: Resources are isolated and secured individually to limit lateral movement within networks.
Least privilege access: Users and systems receive only the minimum permissions necessary to perform their functions and only for the required duration.
Continuous verification: Every access request must be authenticated and authorized before granting access, regardless of the user's location or the resource being accessed.
Comprehensive monitoring: Continuous monitoring and analysis of all network traffic and activities enables rapid threat detection and response.
If we were to claim that those principles cover the what in what we need to do to get to Zero Trust, then the where that we apply those principles is specified by the so-called pillars of Zero Trust.
The pillars of Zero Trust
Not surprisingly, there have initially been several interpretations2 of Zero Trust, which has resulted in slightly different pillar definitions. In the end, Zero Trust pillars span the entire breadth of enterprise operations.
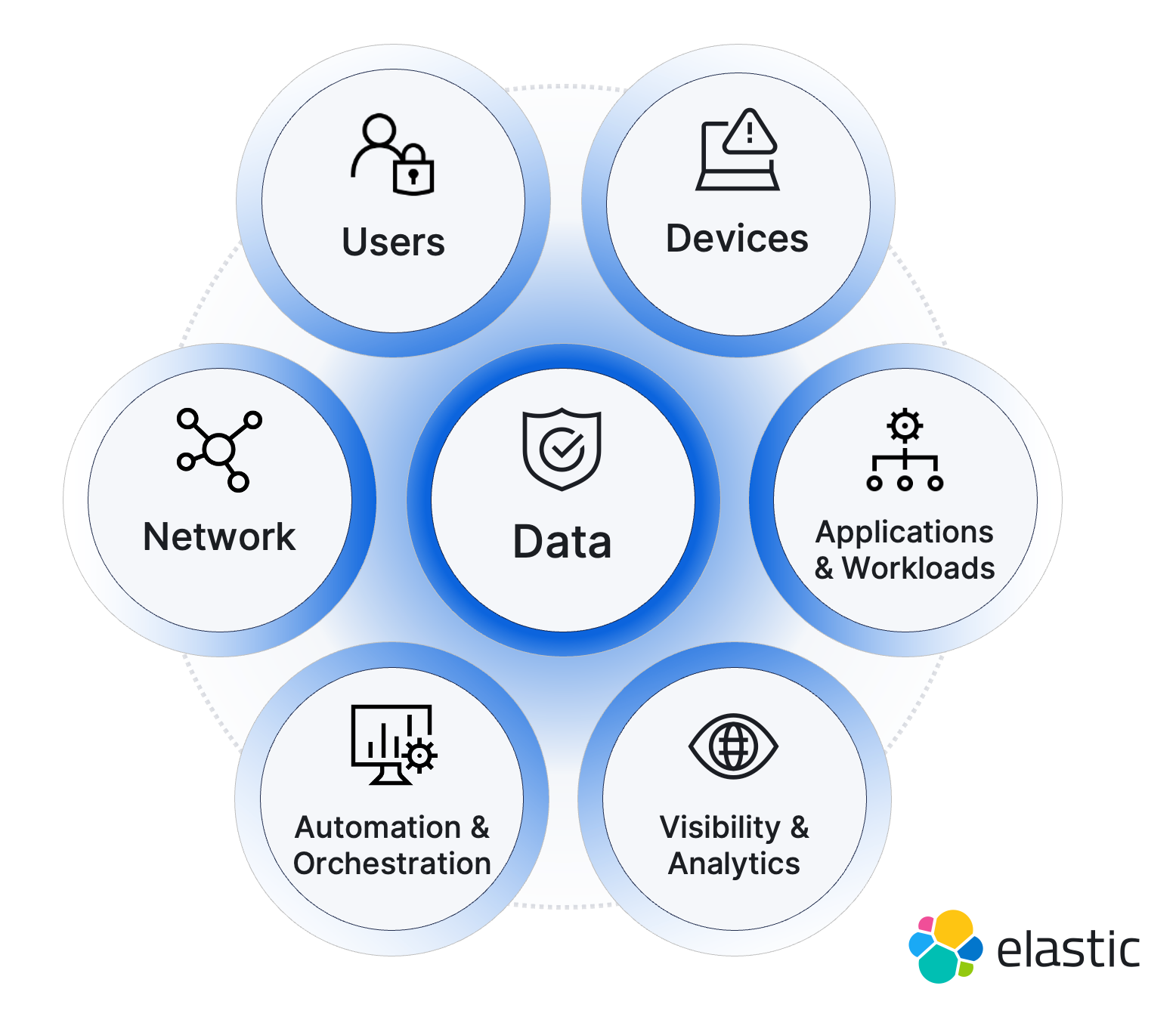
Let’s use the US Department of Defense’s (DOD’s) pillars as our baseline to describe the pillars of Zero Trust:
Users: Almost all ZT decisions are predicated on properly identifying who the entity is that’s requesting a given transaction. It’s called “identity-centric security” after all.
Devices: Users typically interface with other systems in the environment through a device of some sort, and the characteristics of that device (especially any system vulnerabilities) affect ZT decisions. Devices also offer a convenient policy/decision enforcement point.
Network: The network is the connective tissue between the systems that make up the IT environment; all interactivity between systems occurs through the network.
Data: Data is really the prime target of bad actors. Whether their goal is to steal it or to prevent it being accessed, the organization’s data is the crown jewel that we’re trying to protect.
Applications and workloads: The applications and workloads being run are the traces of the main activities flowing between the users/devices and the data repositories being accessed over the network. We need to account for any vulnerabilities in those applications so that we can watch out for and protect from attacks on those fronts.
Automation and orchestration: Automated or orchestrated systems can be easily forgotten when planning the ZT strategy, but because these systems are expected to make decisions on our behalf (via automation), we need to make sure they are doing so as we expect and haven’t themselves been compromised.
Visibility and analytics: It almost goes without saying, but you can’t verify or measure something that you aren’t tracking, so continuous monitoring of all of the above systems plays a vital role in effective Zero Trust.
Interestingly, the pillars of Zero Trust represent both the systems that are to be monitored and protected as well as being key sources of information for making Zero Trust decisions.
Those broad pillars cover most of the mission critical systems in any IT environment pretty well, so now we have what principles we’re applying and to where. But the trouble we’re all facing now is in how we achieve the practical implementation of these principles across all of those diverse systems.
The implications of “never trust, always verify”
Zero Trust requires a much more active and comprehensive approach to security.
The ultimate ideal of Zero Trust is that every transaction needs to be monitored and approved.
There are as many potential problems as there are systems to integrate when we want to make Zero Trust a reality, but we can group them into several broad categories of issues:
Complexity and disparity: There is no one product that does Zero Trust. For ZT to work, it has to involve every one of those systems working together in a coordinated fashion. The problem is that none of those systems were designed to be that interoperable.
Speed: How will that level of scrutiny affect the speed of operations? The additional burden to capture, monitor, and check every transaction could slow operations to the point of unusability. The speed factor actually highlights a hidden implication of Zero Trust; it’s “turtles all the way down,” meaning that you can only get so granular with the concept of never trust, always verify until the speed at which you can maintain usable operations becomes untenable. What this means is that at various points, we will have to accept some measure of trust in the form of either perimeter security at the application/endpoint level or perhaps a time-bound ZT decision cache), but it will at least be constrained to a much smaller attack surface through ZT segmentation and governance rules.
Fragility: Whenever the communications between disparate systems depend on individual point-to-point integrations or federation technologies (think translation services), an element of brittleness gets introduced. Enterprise systems cannot remain frozen in time; they must eventually be updated for security or efficiency purposes, and those upgrades frequently break or deprecate custom-developed connections and integrations. If that system happens to provide data to multiple parts of the ecosystem, then each of those connections becomes a point of failure.
The ultimate vision of Zero Trust cannot be accomplished through one-off integrations between systems or layers. Short of rewriting every application, protocol, and API schema to support some new common Zero Trust communication specification, there is only one commonality across the pillars: They all produce data in the form of logs, metrics, traces, and alerts. When brought together into an actionable speed layer, the data flowing from and between each pillar can become the basis for making better-informed Zero Trust decisions.
There is only one commonality between the pillars: they all produce data.
Achieve real-time relevance with Elastic’s Search AI Platform
The very first action that every business operation starts with is a search to find the most relevant information for the task: data points for answering the question at hand, raw data to be analyzed and conclusions drawn, and correlated insights to ensure the best decision is made. We need the flexibility to consider all potentially relevant data instead of being limited to only the predetermined formats, data sources, or conclusions that our hard-working data scientists were able to predict might be useful to us. Therefore, real-time operations require real-time search with a system that can ingest any type of data and allow it to be interrogated integrally and interactively. And that’s a search engine.
Distributed search is the foundation
The core capability at the heart of Elastic’s Search AI Platform is distributed search. Instead of forcing your organization to back-haul all data into a centralized repository — usually one that is only good at cost-effective storage and not made for fast flexible search and retrieval — Elastic allows data to be collected and ingested locally into a distributed platform that’s able to search both locally and globally.
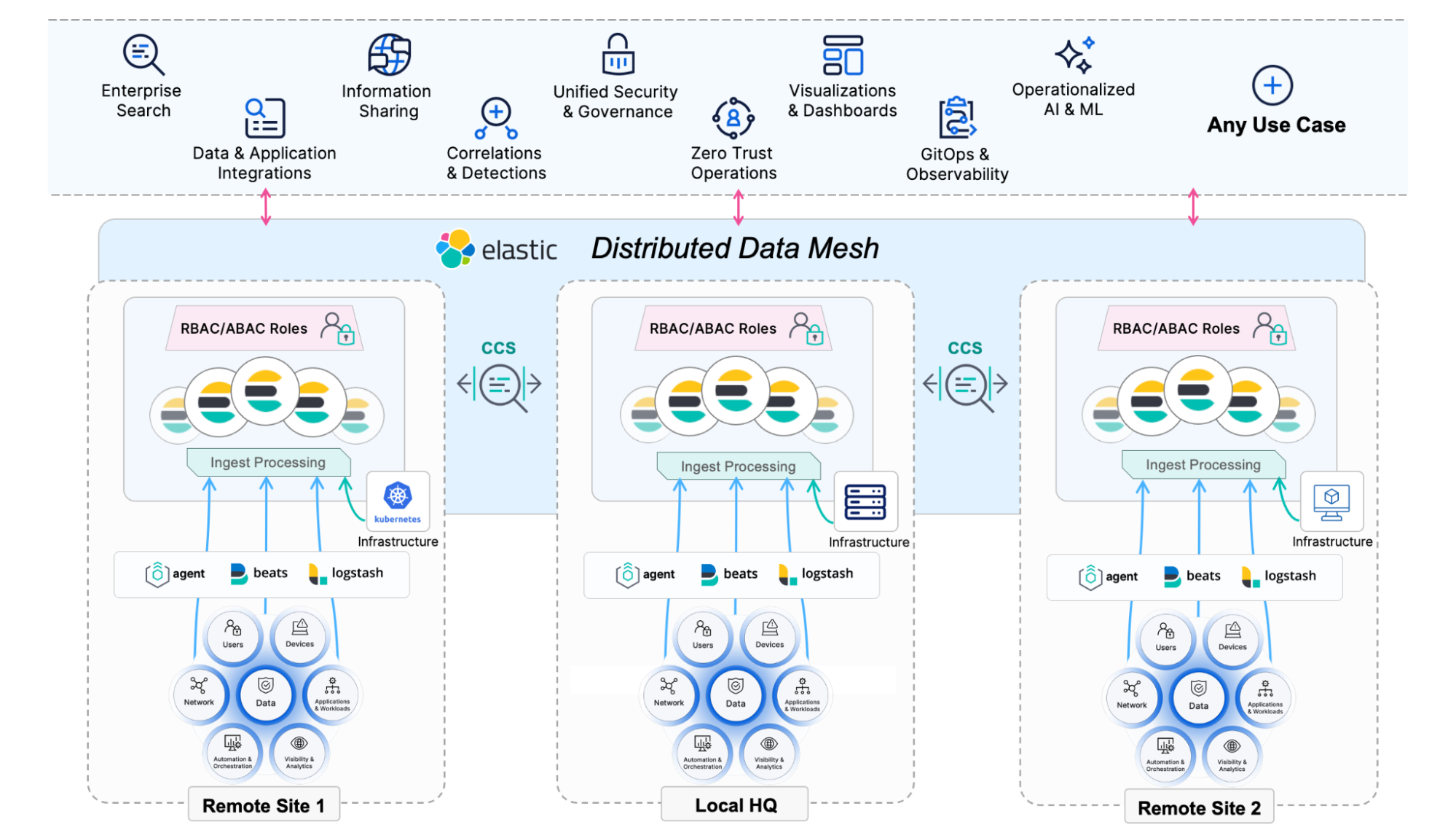
Elastic components deploy and run in a platform-agnostic way. Each Elastic cluster can be deployed to whatever infrastructure is preferred or available at each location, such as bare metal, cloud/VPC, virtualized, or containerized. And they all connect and interact through cross-cluster search (CCS) as if they were all on the same infrastructure. As data is ingested, it can be automatically analyzed/processed through customizable ingest pipelines and normalized to the Elastic Common Schema. Dynamic real-time access to subsets of data within each of those distributed clusters can be configured through integrated role- and attribute-based access controls (RBAC/ABAC) to allow for searching across all instances globally and securely.
Distribution is the core principle behind everything in our Search AI Platform from the way data is spread among nodes in a local cluster to the way remote clusters form larger clusters. This flexibility allows organizations to use parallelized compute resources to grow clusters locally and to dynamically and securely connect to all of their data using the power of internet-speed search.
It’s all in there
On top of this distributed platform are all of the enterprise-grade features your organization requires for ingesting, analyzing, and managing all types of data at huge scales.
Automated near real-time ingestion, processing, normalization, analysis, detection, and alerting on any and all types of data — structured, unstructured, semi-structured, numeric, geospatial, vectorized
Full-spectrum search and analytics — full-text lexical, semantic/vector, and hybrid retrieval, aggregations, and filtering; multiple query modalities to suit any data and use case
Automated data resilience, high-availability, and cost-effective data lifecycle management, including searchable snapshots, which allows data archives to remain fully searchable throughout their entire retention timeframes
Fully integrated unsupervised and supervised machine learning (ML), including the ability to import third-party large language models (LLMs) and apply them to your data streams
The entirety of the stack is built API-first, making it easy to integrate with and allowing Elastic’s Search AI Platform to become a unified data layer spanning all data sources. Our Search AI Platform is a general-purpose distributed data platform that can power any number of use cases and applications.
Search in support of artificial intelligence operations
Nearly every organization today is actively investigating the potential use of artificial intelligence (AI) in multiple aspects of their business operations. The hope for AI is that it will vastly speed up, automate, and improve the scope of large scale data analytics required for everything from basic research to critical decision making. So, it’s no surprise that AI initiatives would be considered within the context of Zero Trust operations as well.
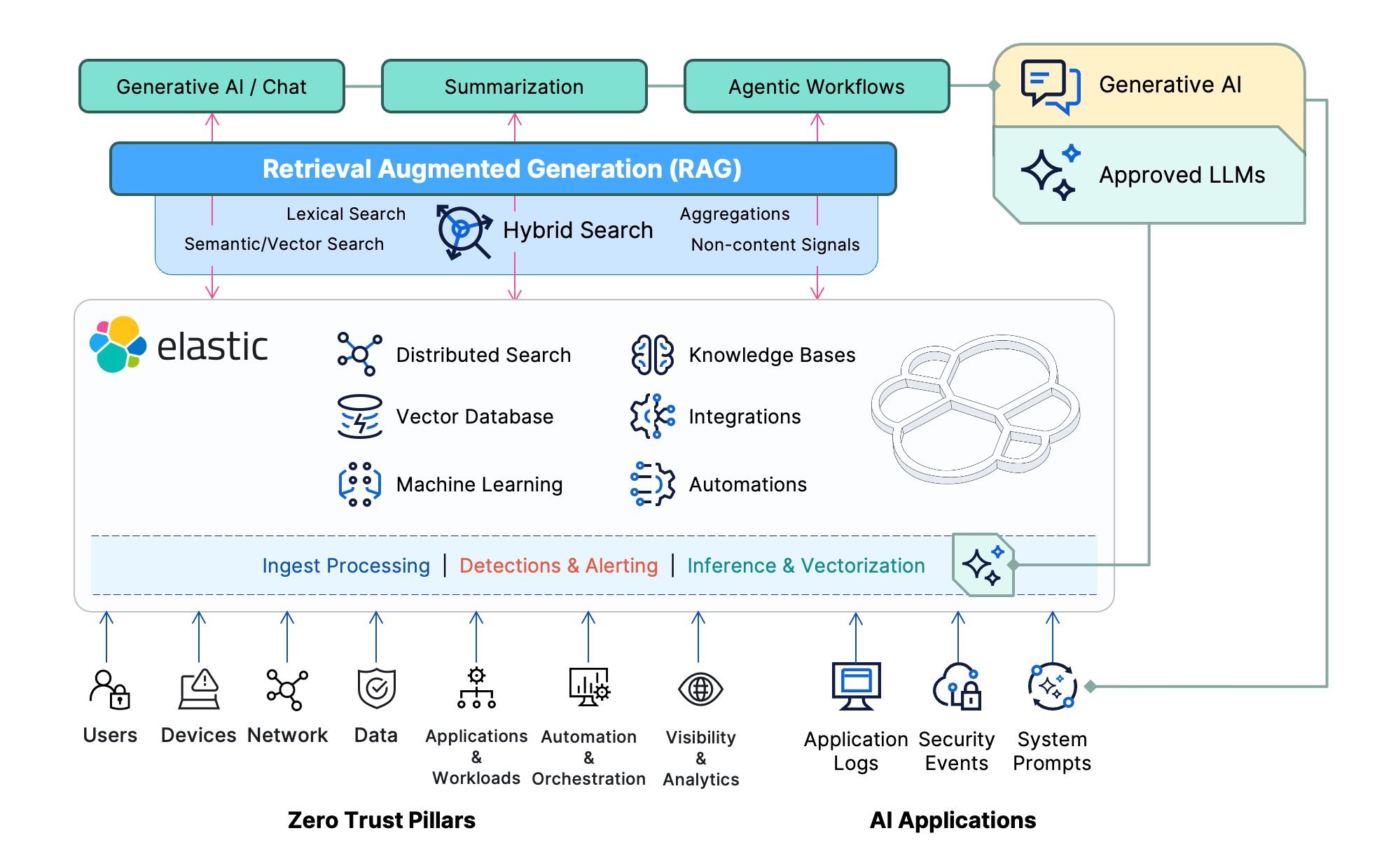
Elastic’s Search AI Platform plays a vital role in grounding AI operations through several techniques broadly known as retrieval augmented generation (RAG). A typical RAG operation performs a prequery to find additional contextual information to include along with the AI prompt that will help constrain or inform the generative AI (GenAI) activity toward better results. Those GenAI prequery activities are exponentially faster, more comprehensive, and more controllable when the RAG operations are based on Elastic.
During indexing, Elastic enables the vectorization (a.k.a. text embedding) of your organization’s knowledge bases using dense and sparse language models to allow searching them semantically. Semantic search gets us all out of the limited keyword-only search world and allows matching on content that is conceptually similar without having to rely on exact terms, synonym lists, or other controlled vocabulary mappings.
In Elastic, vector search can be used together with the full spectrum of lexical query tools provided natively to deliver extremely powerful hybrid search. Hybrid search can further combine multiple query modalities like vector, lexical, and geospatial with aggregations and dynamic reranking strategies through multistage retriever capabilities. And because our Search AI Platform can ingest all types of data, noncontent signals — things like the user’s profile, risk scores, security permissions, time/location, data segmentation policies, and governance controls — can be used to further shape the information sent to GenAI context windows.
Elastic’s capabilities for Zero Trust
For Zero Trust operations to succeed, they must be based on fast, well-informed risk scoring and decision making that takes into account myriad indicators that are continually flowing from all of the pillars. Elastic can immediately upgrade and empower your organization’s Zero Trust posture by providing a unified speed layer for all data.
One of the biggest hurdles with current approaches to Zero Trust is that most ZT implementations attempt to glue together existing systems through point-to-point integrations. While it might seem like the most straightforward way to step into the Zero Trust world, those direct connections can quickly become bottlenecks and even single points of failure. Each system speaks its own language for querying, security, and data format; the systems were also likely not designed to support the additional scale and loads that a ZT security architecture brings. Collecting all data into a common platform where it can be correlated and analyzed together using the same operations is a key solution to this challenge.
Monitoring the Zero Trust pillars and infrastructure
The first and perhaps most important capability Elastic brings to Zero Trust is the ability to monitor and analyze all of the infrastructure, applications, and network involved. Elastic can ingest all of the events, alerts, logs, metrics, traces, host, device, and network data into a common search platform that also includes built-in solutions for observability and security on the same data without needing to duplicate it to support multiple use cases. This allows the monitoring of performance and security not only for the pillar systems and data but also for the infrastructure and applications performing Zero Trust operations.
Let’s use an example. Within the conceptual ZT users pillar will likely be an Identity, Credential, and Access Management (ICAM) system that is used to verify and control user/entity access and permissions. There might also be a User and Entity Behavior Analytics (UEBA) system that analyzes the traces of activities a given user (correlated to an ICAM-validated account) leaves in various systems. UEBA looks for suspicious or unusual behaviors for that account either based on their normal activity baseline or in comparison to other entities of a similar role/permissions level.
From a Zero Trust monitoring context, Elastic could:
Index application logs from the ICAM, UEBA, and any other systems in the users pillar
Automate the capture of system metrics using a variety of approaches, including OpenTelemetry, and use them to report on system uptime, performance, and SLOs
Monitor network flows in and out of the users pillar
Ingest and correlate processing traces from the users pillar applications themselves
Collect logs and metrics on the various infrastructure and orchestration platforms that the users pillar systems are deployed on
- Use its built-in observability and security solutions in service to the Zero Trust visibility and analytics pillar
Data-driven risk scoring
With data from each pillar ingested into a common speed layer (and one that doesn’t add additional query load to the underlying data systems/repositories), we can cross-correlate signals across sources to automatically detect suspicious behavioral indicators and then use them to adjust risk scoring on the actors within our Zero Trust Architecture.
Originally developed as part of the built-in Elastic Security solution, the Search AI Platform includes a general-purpose detection engine that can be used on any type of data. Detection rules use several different query mechanisms, including standard query syntax (DSL); event sequences (EQL); piped queries (ES|QL); and even anomalies found through built-in machine learning, to correlate and identify patterns within incoming data streams and fire alerts on the matches.
Detection rule alerts get stored into their own index and can also immediately trigger additional alert-based actions to third-party systems and integrations like SOAR or ticketing systems. There currently are over 1,100 prebuilt detection rules that have been developed, curated, and tested by the Elastic Security Labs team, but those rules are open source and easily duplicated and edited to suit the data streams and parameters of the implementation.
Whether it’s using the existing risk scoring mechanisms in the Elastic entity store or purpose-built objects for the customer’s Zero Trust implementation, Elastic’s Search AI Platform provides the flexibility to build risk scoring indices to track and query any type of entity. Again, perhaps some examples would help illustrate the possibilities:
Users: Individual or service accounts can have unsupervised ML jobs tracking their access requests throughout the systems and fire anomalies on unusual requests that are then used to adjust the entity’s overall risk score (and possibly to alert a UEBA system).
Devices: Whenever a compliance scan is run on a given device, the resulting report could also be used to adjust the device’s risk score index.
Network: Unusual volumes or types of traffic between network nodes might fire an alert to adjust the risk score for that network route and perhaps to send traffic through alternate systems with deeper inspection.
Data: Because Elastic includes a number of hybrid search and AI-driven data analysis capabilities, we can use various methods to characterize and categorize the data within each repository (especially powerful for unstructured sources) and generate or update its overall risk score.
Applications and workloads: Elastic can keep an inventory of our application versions, dependencies, and vulnerabilities otherwise known as a Software Bill of Materials (SBOM) to assign risk scores for certain types of interactions and align those with the requests being made to them.
Automation and orchestration: The infrastructure, orchestration, and automation platforms themselves can introduce risk into the Zero Trust landscape; perhaps any process that’s not vetted by human oversight should get a slightly higher risk score associated with it.
Visibility and analytics: Sudden changes in system performance and/or the level of observability of a system (or lack thereof) could factor into the risk profile given to a Zero Trust transaction.
You might also be wondering if a search platform is able to keep up the pace with all those activities — after all, Elasticsearch was really not created to be a transactional database. That question is actually related to a classic database design decision about whether to normalize or denormalize the data structures. Normalizing them reduces potential data duplication by keeping one table for a set of related fields and combining them through relational fields. Denormalizing them stores and renders data in a form that’s best suited for searching it quickly.
Elastic can handle a lot! Some of our customers ingest multiple millions of records per second, but it’s not meant for constantly updating the same record over and over again with a new value. What Elastic is exceptionally good at is operationalizing data and making it readily available for near real-time search and analytics at huge scales.
Elastic is exceptionally good at operationalizing data
What this means is that in practice, just like with any other system, it’s likely that a trade off in terms of fidelity (i.e., how often the score is updated) will be necessary for some of those risk score calculations. But that’s all part of the decision tree when we’re evaluating accuracy versus performance for a real-world operational system. How much performance impact can be allowed and still make the accuracy acceptable?
Powering Zero Trust itself
If the ultimate goal of a Zero Trust Architecture is to observe and validate that every transaction within the system is authorized (not implicitly trusted), what would that look like? When we have all of our systems being actively monitored and are able to assign dynamic risk scoring to the components of our Zero Trust Architecture, that means we’re almost there!
Many Zero Trust decisions could be distilled down to a relatively straightforward formula: If the criteria are met, allow the transaction to proceed; if not, block it. The risk scores become inputs into our formula:
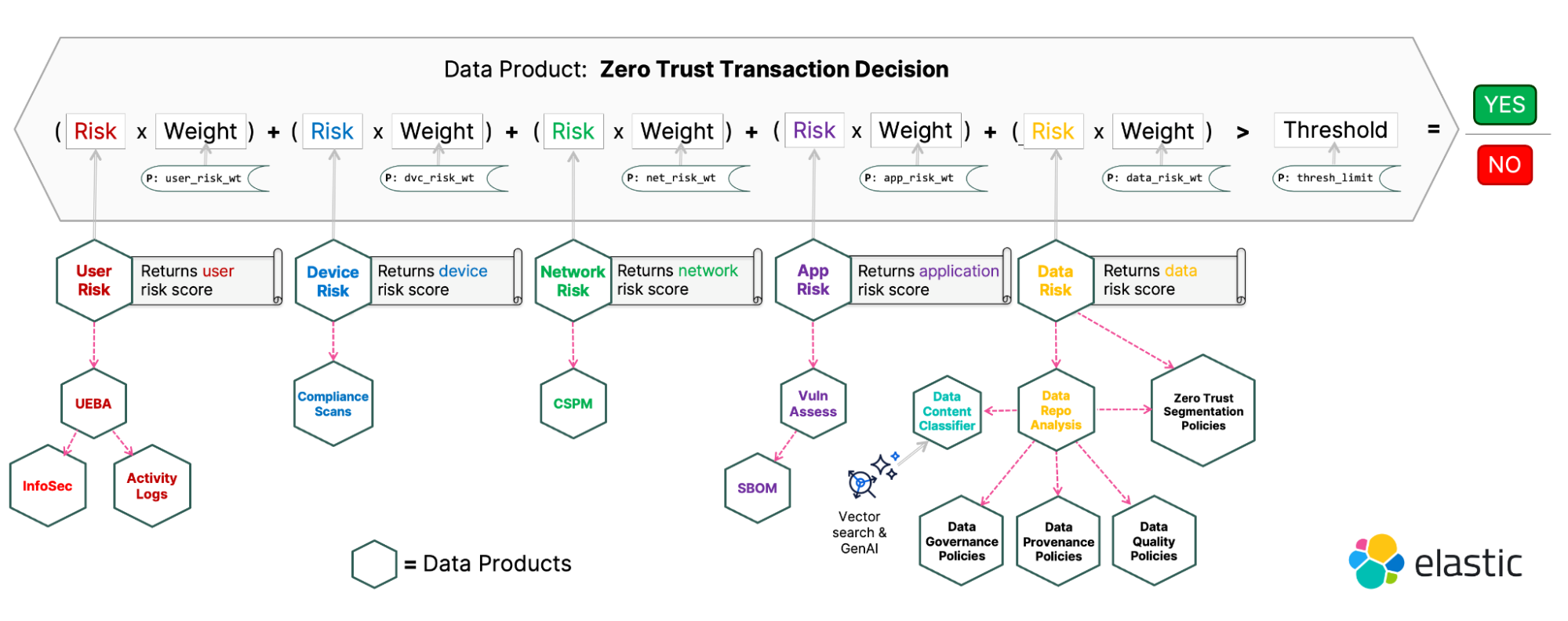
The construct that contains the formula is called a data product. It’s essentially an endpoint that returns a discrete unit of information that’s been shaped, culled, and refined by a data domain owner that has a vested interest in delivering a high-quality result built on the data that resides in their domain. Data products are usually tailor-made to answer very specific questions and can be composed of queries to a single source, multiple sources, or other data products.
In the realm of Zero Trust, we could have rather complex chains of data products built on other data products. For example, a data product that returns an account’s current risk score (the user pillar) could be based on the outputs from other data products that check the user’s status in the organizational UEBA system or whether they’re flagged for active insider threat investigations.
Another data product that returns the risk score for a requested repository (the data pillar) could correlate the authorizations of the user making the request with the risk scores assigned by the organization’s Zero Trust macro/micro-segmentation rules, which identify and govern the most sensitive data in the organization. Without a unified data speed layer like Elastic, individual connections would have to be manually made to each repository to extract, translate, and correlate every disparate piece of the formula — a process that is fragile, slow, and could potentially lock up Zero Trust operations that need reliability and speed.
The key to Zero Trust success: Integrate and operationalize your data
The Zero Trust security paradigm is absolutely necessary; we can no longer rely on simplistic perimeter-based security. But the requirements demanded by the Zero Trust principles are too complex to accomplish with point-to-point integrations between systems or layers. Zero Trust requires integration across all pillars at the data level. Elastic’s Search AI Platform provides exactly that: fast operationalized data that’s able to be used in any way the organization needs.
Start your free trial today. Learn more about how Elastic helps in your organization’s Zero Trust journey:
Sources
1. Cybersecurity Magazine, “Zero Trust Security Architecture,” 2022.
2. Cybersecurity & Infrastructure Security Agency, “Zero Trust Maturity Model,” 2023. | National Institute of Standards and Technology, “Zero Trust 101,” 2020. | U.S. Department of Defense, “DoD Zero Trust Strategy,” 2022. | U.S. General Services Administration, “Zero Trust Architecture (ZTA) Buyer’s Guide,” 2025.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third-party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, and associated marks are trademarks, logos, or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print