Beobachtbarkeit im KI-Maßstab zu einem Bruchteil der Kosten
Elastic Observability sammelt nicht nur Daten – es versteht Ihre Systeme, erkennt, was wichtig ist, und ergreift Maßnahmen. Schneller und günstiger als die Alternativen.
Innovationstreiber für 50 % der „Fortune 500“-Unternehmen
Beobachtbarkeit, die Ihr System kennt
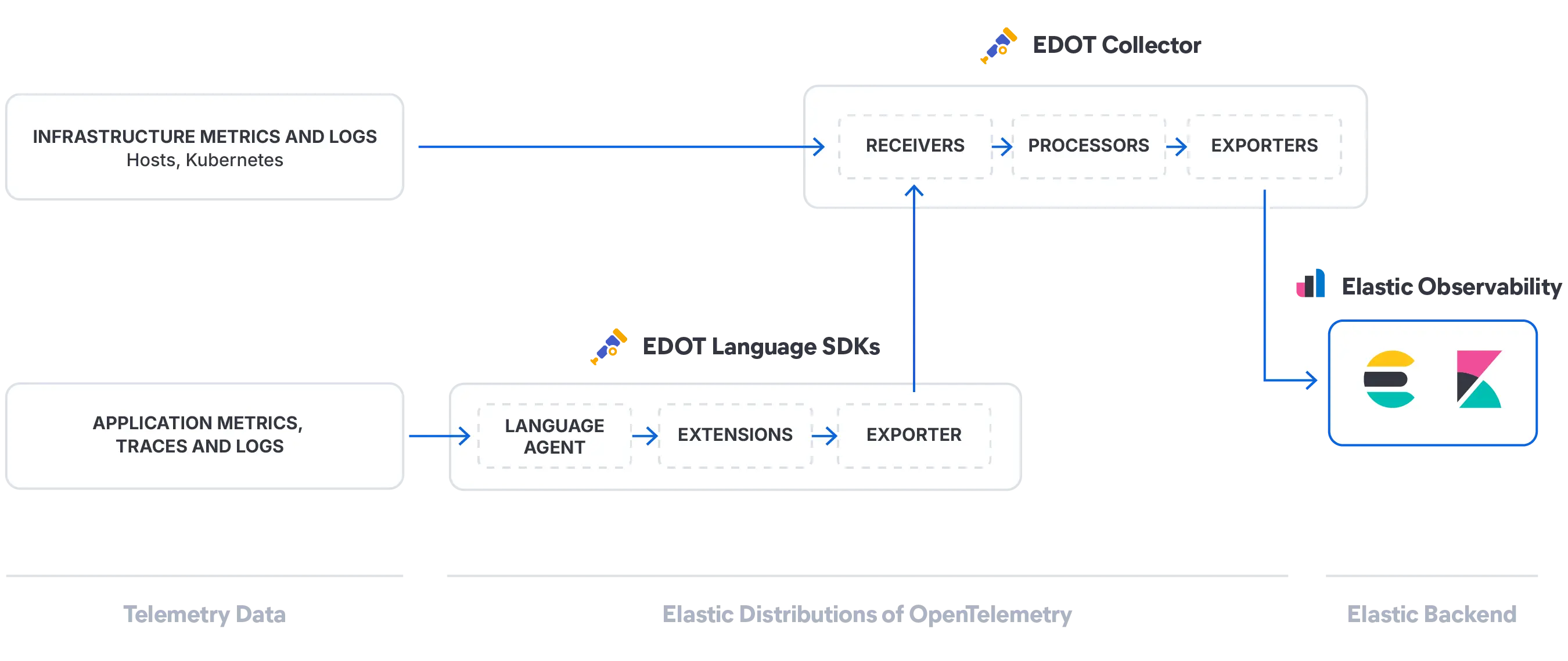
Elastic verwandelt Ihre Logs, Metriken und Traces in ein Live-Systemmodell, das KI in Echtzeit analysieren kann. Verfügbar auf Anfrage über jede beliebige KI-Schnittstelle Ihrer Wahl.
Eine Plattform für alles
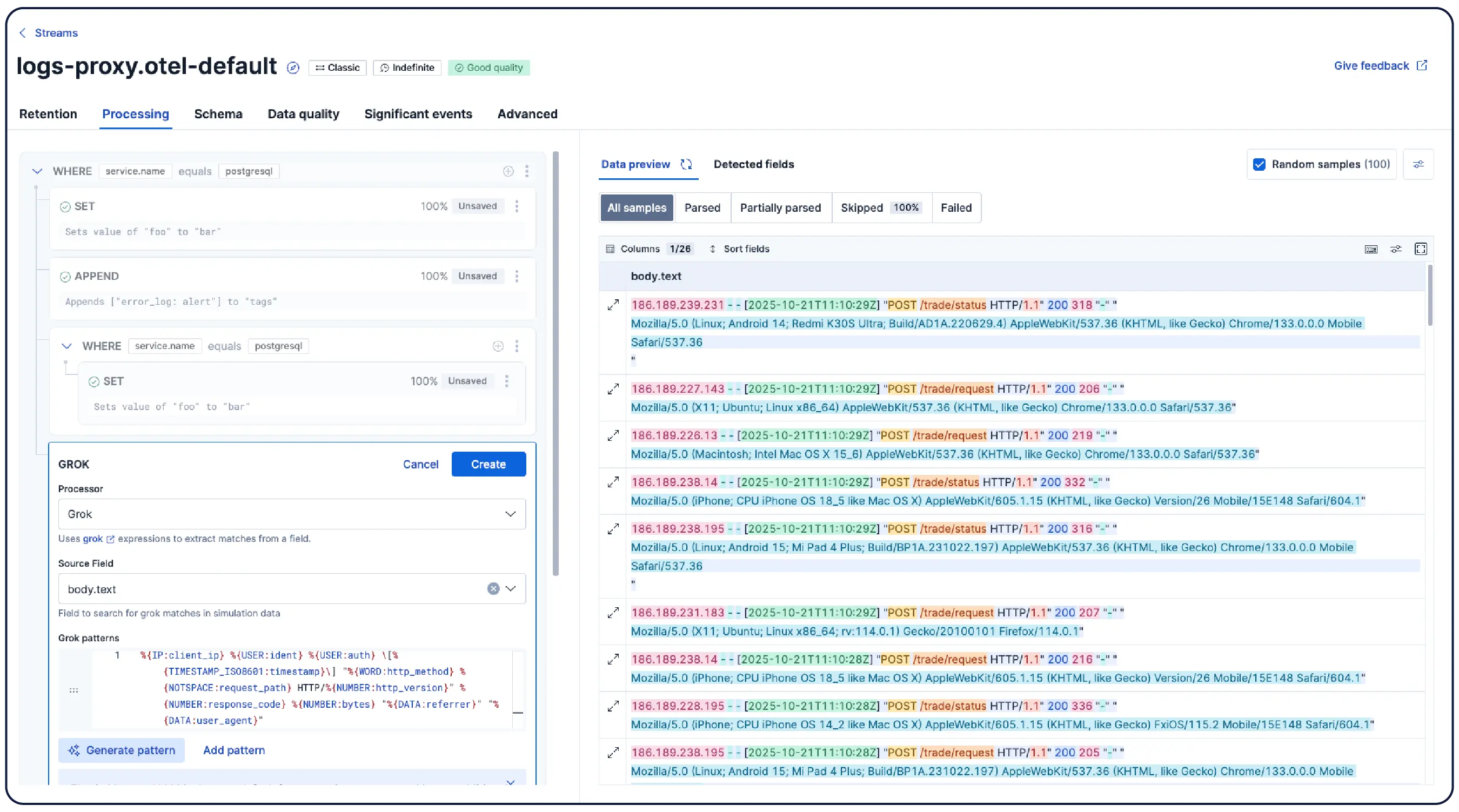
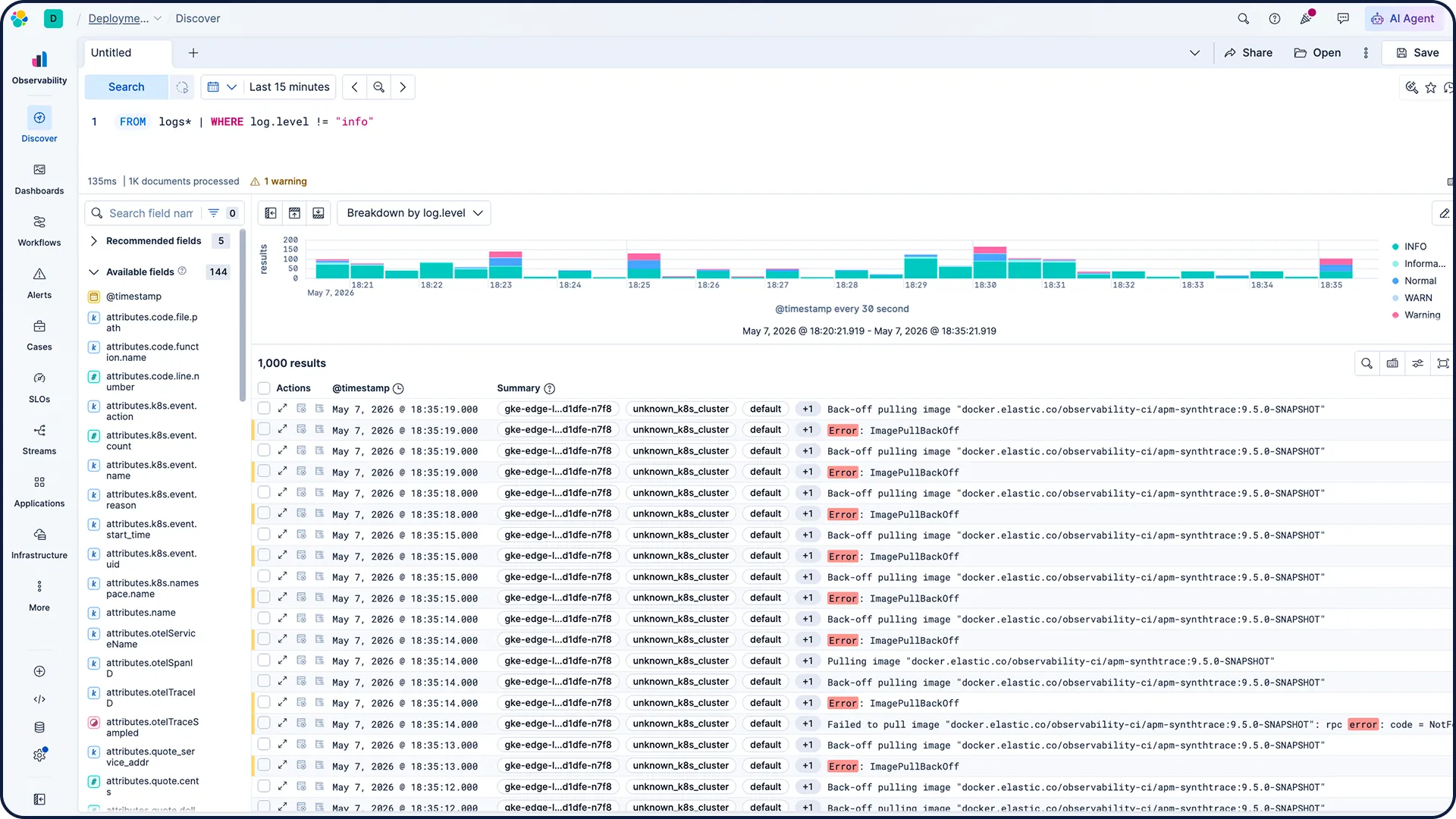
Alle Signale, eine zentrale Informationsquelle – mit Logs im Zentrum der Untersuchungen.
Mehr als 450 Integrationen mit nur einem Klick für Clouds, CI/CD, Datenbanken und mehr.
Die Innovation hinter den Ansprüchen
Erstklassige Effizienz
KI ist nur so gut wie die Datenplattform, die sie antreibt. Von der Speicherarchitektur bis zur Abfrageleistung: jeder Teil von Elasticsearch wurde für einen bestimmten Zweck entwickelt.
Ein speziell entwickelter Indexmodus für Log-Daten. Intelligente Sortierung nach host.name und @timestamp platziert ähnliche Einträge nebeneinander, was die Kompression dramatisch verbessert. Synthetic _source rekonstruiert Felder auf Anfrage. Lesen Sie den ausführlichen Artikel →
langfristige Log-Aufbewahrung bis zu 50 %
intelligente Indexsortierung bis zu 30 %
In Version 9.x vereinen sich vier gezielte Optimierungen der Abfrage-Engine und erzielen seit Januar 2026 eine um 40 % bessere Latenz.
Der Modus „Nur Dokumentwerte“, der im Laufe dieses Jahres auf den Markt kommt, verzichtet vollständig auf invertierte Indizes und BKD-Bäume und verwendet komprimierte binäre Dokumentwerte, um eine nahezu spaltenbasierte Speicherdichte zu erreichen.
Sind Sie bereit für den Wechsel?
Wechseln Sie von Datadog und sparen Sie 50 % Ihrer Kosten für Metriken.
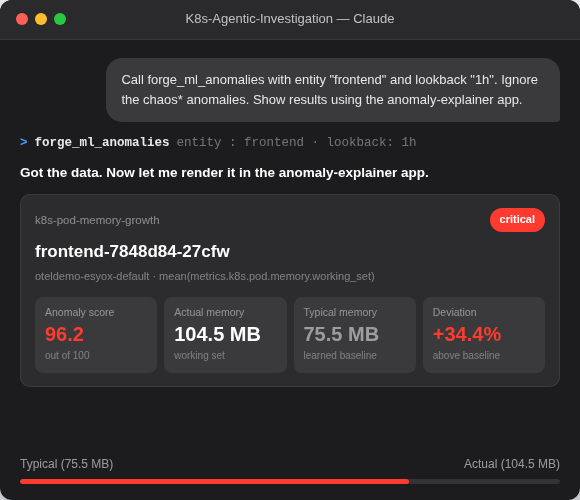
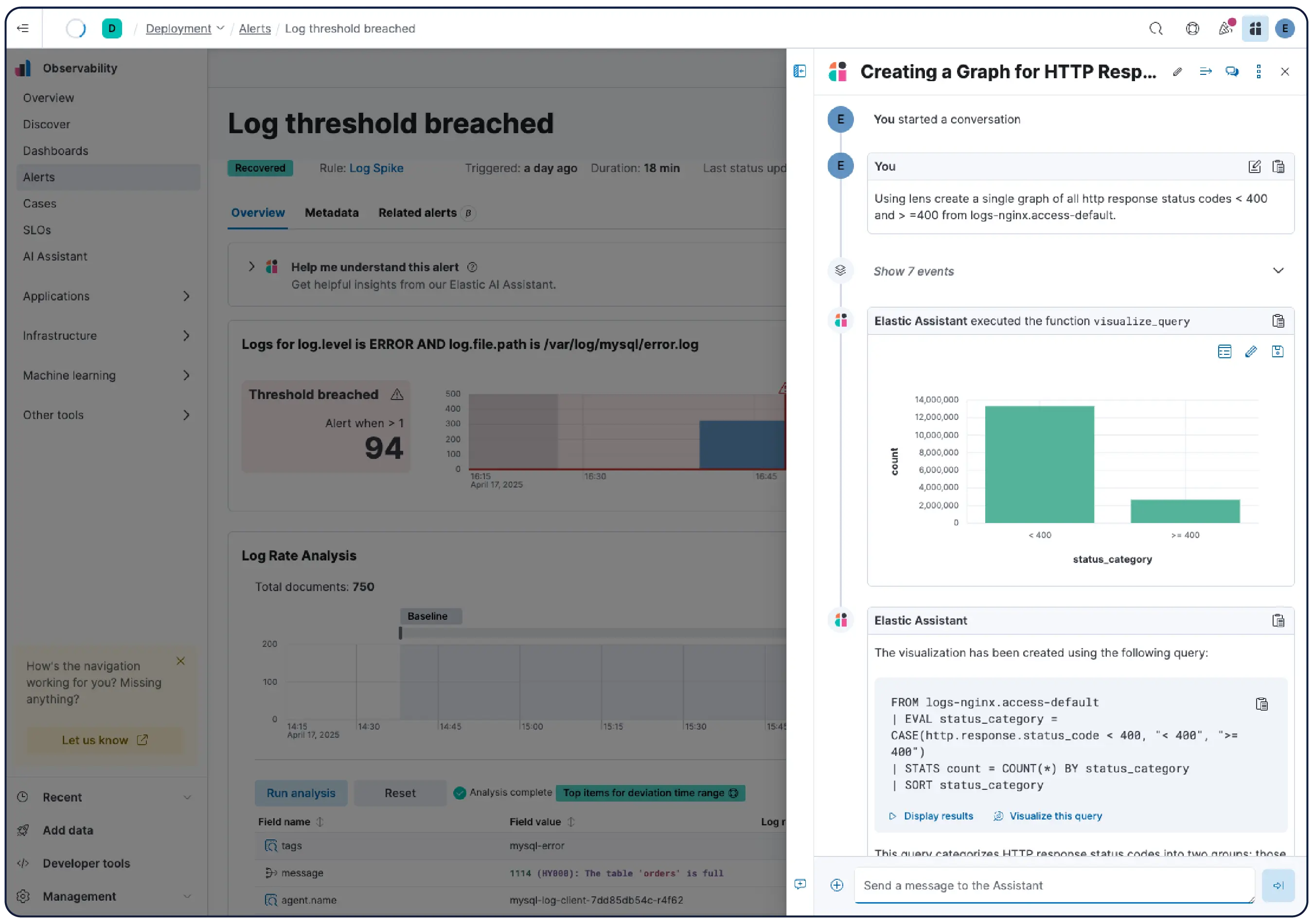
Der Untersuchungskontext, den Ihre KI benötigt
Elastic extrahiert automatisch Wissensindikatoren (Knowledge Indicators, KIs) aus Ihren Telemetriedaten – Entitäten, Abhängigkeiten, Live-Status und Kontext – und erstellt so ein kontinuierlich aktualisiertes Modell Ihres gesamten Systems. Keine Konfiguration oder Kennzeichnung erforderlich.
Weitere Informationen →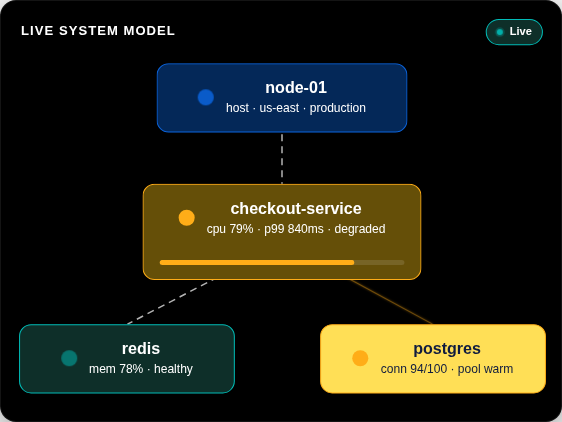
Beobachtbarkeit überall da, wo Sie bereits arbeiten
Die gleiche Intelligenz – KIs, wichtige Ereignisse und Abhilfemaßnahmen – auf jeder Oberfläche dargestellt. Kibana für Ihr SRE-Team. Claude für Ihren Bereitschaftsingenieur. CLI für Ihre Automatisierungspipeline.
MCP-Server abrufen →-
 Nativer MCP-Server
Nativer MCP-Server
-
Fähigkeiten werden automatisch geladen
-
Oberflächenbewusstes Rendering
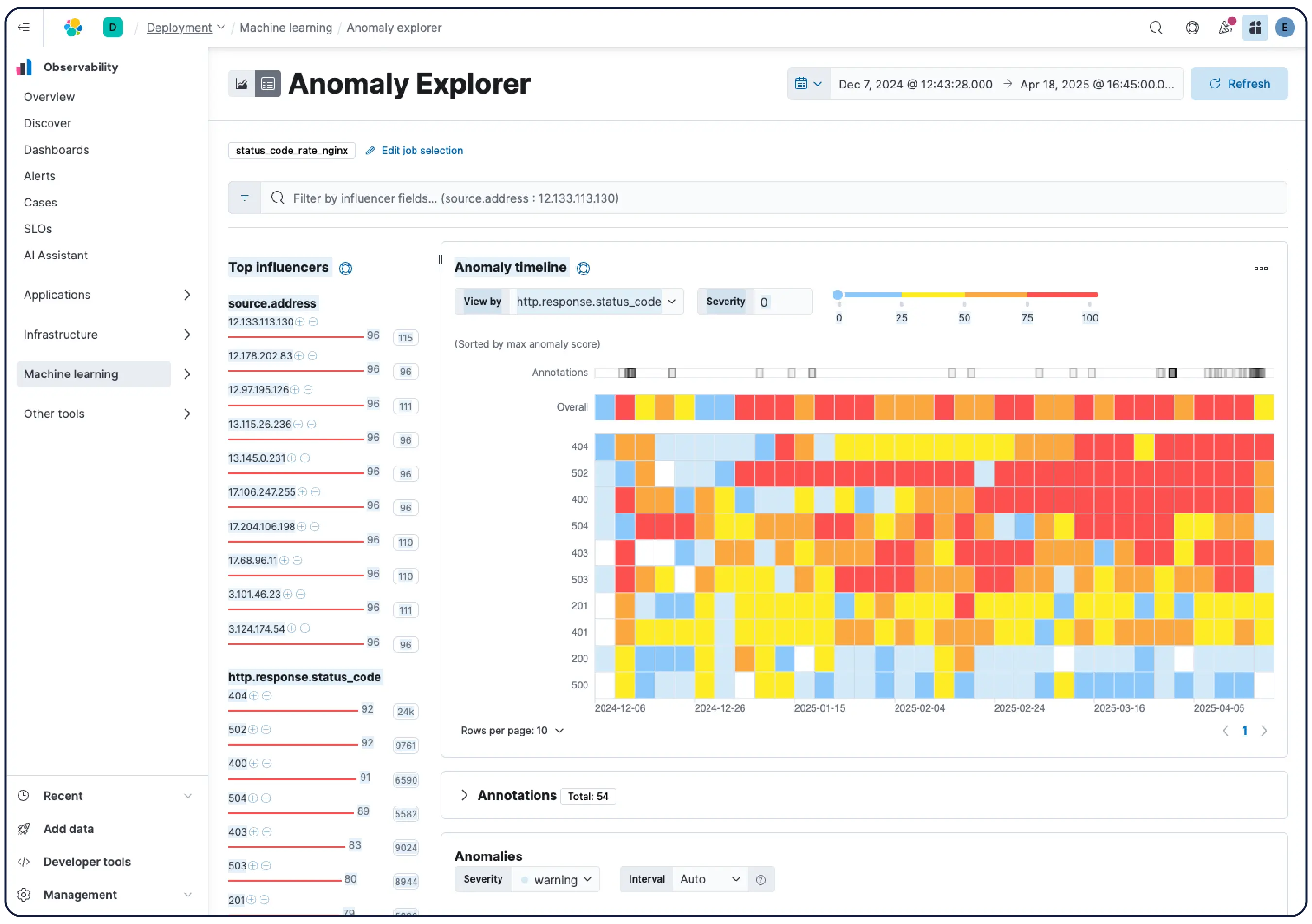
Von Daten zu Antworten. Ganz ohne Aufwand.
Von der Log-Analyse bis hin zu agentenbasierten Untersuchungen – alles basiert auf der realen Denk- und Arbeitsweise von SREs.
Am Chat teilnehmen
Verbinden Sie sich mit der globalen Community von Elastic und nehmen Sie an offenen Gesprächen und an der Zusammenarbeit teil.
Diskutieren
Stellen Sie Fragen, erhalten Sie Antworten und verschaffen Sie sich Gehör in unserem offenen Forum.
In unserem Forum posten →Slack
Fachsimpeln. Notizen austauschen. Gestalten Sie die Zukunft von Elastic Observability.
Treten Sie unserem Slack bei →GitHub-Repo
Erkunden Sie, bringen Sie sich ein und schlagen Sie Verbesserungen vor.
Projekte erkunden →Meetup
Tauchen Sie in Elastic ein. Lernen Sie, erkunden Sie und treten Sie mit Gleichgesinnten in Kontakt.
An einem Meetup teilnehmenHäufig gestellte Fragen
Full-Stack-Observability (Beobachtbarkeit für den gesamten Stack) bezeichnet die Fähigkeit einer Observability-Lösung, den gesamten Anwendungs-Stack zu überwachen – vom Endnutzer bis zum Anwendungscode und zur Infrastruktur. Eine Full-Stack-Observability-Lösung besteht in der Regel aus mehreren Komponenten für Zwecke wie das Monitoring und Analysieren von Logdaten, das Monitoring der Cloud und der Infrastruktur, das Monitoring der Anwendungsleistung, das Monitoring der digitalen Experience, kontinuierliches Profiling und AIOps. Nehmen Sie an unserer Selbsteinschätzung teil, um zu verstehen, wie Sie auf Ihrem Weg zu einer einheitlichen Full-Stack-Observability-Plattform abschneiden, damit Sie Telemetriedaten ganzheitlich analysieren und eine schnellere mittlere Zeit bis zur Lösung erreichen können.
Agentenbasierte Beobachtbarkeit ist ein Ansatz, bei dem KI-Agenten Vorfälle aktiv untersuchen, anstatt darauf zu warten, dass Ingenieure Dashboards und Warnungen interpretieren. Anstatt lediglich Daten bereitzustellen und es den Menschen zu überlassen, die Zusammenhänge herzustellen, analysieren KI-Agenten Ihre Telemetriedaten in Echtzeit – sie identifizieren die Ursache, korrelieren Signale über verschiedene Dienste hinweg und empfehlen oder führen Abhilfemaßnahmen aus.
KI-gestützte Observability ermöglicht es Unternehmen, geschäftliche und operative Exzellenz zu erreichen. Durch die Implementierung einer Full-Stack-Beobachtbarkeit, die auf agentischer KI basiert, können SRE-Teams Probleme proaktiv schneller erkennen und beheben – dank kontextbezogener Ursachenanalyse, Korrelation von Signalen über verschiedene Bereiche hinweg und effektiver Zusammenarbeit zwischen isolierten Teams. Die Einhaltung von SLAs wird einfacher und Unternehmen können ihre Time-to-Market verkürzen, ihre operative Effizienz erhöhen und die Kundenzufriedenheit stärken. Erfahren Sie mehr über die Vorteile von KI-gesteuerter Beobachtbarkeit.
Unternehmen weltweit befinden sich in einem schwierigen Umfeld, das von steigendem Kostendruck in Kombination mit großen Datenvolumen geprägt ist, die von komplexen, verteilten cloudnativen Umgebungen generiert werden. Daher benötigen Teams intelligentere Analytics, Zugriff und Aufbewahrung für alle Daten, sofort und von jedem Ort aus, um Probleme lösen, Entscheidungen treffen und Resilienz sicherstellen zu können. Viele Unternehmen, die Splunk Enterprise nutzen, stehen nun vor einer Entscheidung, da Splunk mit Splunk Enterprise, Splunk Cloud und Splunk Observability fragmentierte Beobachtbarkeit mit unterschiedlichen Preismodellen bietet. Dagegen steht das Angebot von Elastic mit seiner schnellen und einfachen Lösung, mit der Unternehmen für die Zukunft gerüstet sind.
Der häufigste Grund: Kosten. Die bei Datadog pro Host und pro Metrik berechneten Kosten steigen mit zunehmender Skalierung der Infrastruktur rapide an, sodass viele Teams vor der schwierigen Entscheidung stehen, welche Daten sie behalten und welche sie verwerfen sollen. Das Modell von Elastic bietet Teams mehr Kontrolle darüber, welche Daten sie speichern, wie lange sie diese aufbewahren und wie viel sie dafür bezahlen – was häufig zu Einsparungen von bis zu 4-fach führt.
Observability kann man sich als Evolution des Monitorings für moderne Anwendungen vorstellen. Im Grunde genommen handelt es sich dabei um die Fähigkeit von Anwendungen und Infrastruktur, mittels verwertbarer Logdaten, veröffentlichter Metriken und verteilter Traces Informationen über ihren inneren Zustand preiszugeben. Durch die Kombination aus Erfassung, Umwandlung, Korrelierung, Analyse und Visualisierung von Signalen ist Observability als Herangehensweise besser für die Komplexität und Größe cloudnativer Umgebungen geeignet als das herkömmliche Monitoring. Observability erfährt mit dem Aufkommen neuer Trends und Technologien eine kontinuierliche Weiterentwicklung.
Die Zukunft der Beobachtbarkeit vorantreiben
Erfahren Sie, warum Elastic im 2026 Gartner® Magic Quadrant™ for Observability Platforms als führend eingestuft wurde.