RAG with context you can trust
AI applications must deliver accurate results at scale to build user trust. Ground large language models (LLMs) with the accuracy of Elasticsearch hybrid retrieval, and scale retrieval augmented generation (RAG) that's low latency and high efficiency.
RAG built for unmatched accuracy and efficient vector scaling
Deliver the right context with the vector performance, cost efficiency, and security that production demands.
Give your RAG applications the right context with hybrid search, semantic reranking, and built-in inference using third-party or native best-in-class Jina AI models. Replace naive vector-only retrieval with a single query that mixes keywords, vectors, and filters.

Scale context across billions of documents spanning structured, unstructured, and vector data without forcing a tradeoff between recall quality and spend. Quantization and disk-optimized algorithms like DiskBBQ reduce memory by up to 95% while maintaining high ranking quality at low latency.

Simplify your pipeline with a unified platform that pulls context from documents and unstructured and structured records in a single query. Enforce document-level and role-based access controls so LLMs only expose data a user should see.
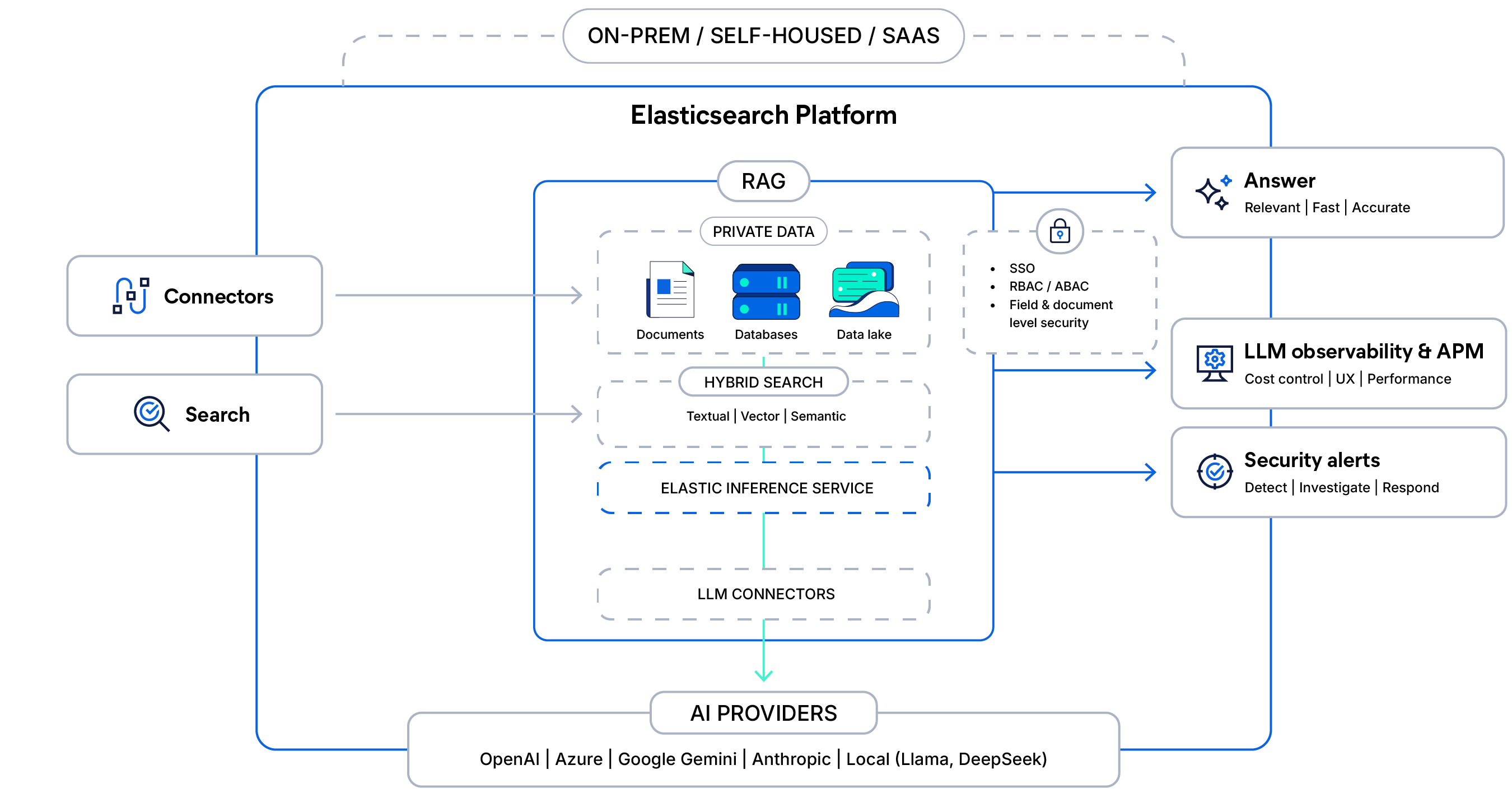
The architecture behind context‑aware RAG
Connect your private data with secure hybrid search and managed inference, ground LLM responses with access controls, and deliver fast, observable, production-ready answers at scale.
What are you building?
Build chat grounded in your data and agents guided by context. Explore our full training catalog or follow along with our tutorials on Elasticsearch Labs.

Q&A on your data. Build a RAG system with Gemma, Hugging Face, and Elasticsearch.

Elastic built a GenAI Support Assistant — explore the architecture, techniques, and best practices to create your own.
Frequently asked questions
What is RAG in AI?
What is RAG in AI?
Retrieval augmented generation (commonly referred to as RAG) is a natural language processing pattern that enables enterprises to search proprietary data sources and provide context that grounds large language models. This allows for more accurate, real-time responses in generative AI (GenAI) applications.
What are the benefits of RAG?
What are the benefits of RAG?
When implemented optimally, RAG provides secure access to relevant, domain-specific proprietary data in real time. It can reduce the incidence of hallucination in generative AI applications and increase the precision of responses.
What are the benefits of using Elastic for RAG workflows?
What are the benefits of using Elastic for RAG workflows?
Elastic makes RAG production-ready by solving the hardest parts out of the box: ingesting and grounding high-quality data, delivering accurate and efficient retrieval at scale, enforcing role- and document-level security, and preserving source attribution for trustworthy responses. With native vector, lexical, and hybrid retrieval; first-party models like ELSER and flexible third-party model integrations across the GenAI ecosystem; and proven performance at enterprise scale, Elastic helps teams build RAG systems that are faster to launch, easier to tune, and reliable in production.
How does Elasticsearch enable context engineering?
How does Elasticsearch enable context engineering?
Elasticsearch is built for relevance at scale, which is the foundation of context engineering. It brings together vector, keyword, and structured search with analytics, inference, and observability in a single platform. This makes it easy for developers to store, retrieve, and rank structured and unstructured business data with precision, so agents always get the right context.
With Agent Builder, Elasticsearch takes this further by bringing chat, retrieval, tool creation, and orchestration directly into the platform. Developers can build, test, and scale context-driven agents in minutes using their own data, models, and tools, all supported by Elasticsearch relevance, security, and performance.