¿Qué son los modelos de lenguaje grandes (LLMs)?
Definición de modelo de lenguaje grande
En su núcleo, un modelo de lenguaje grande (LLM) es un modelo entrenado con algoritmos de aprendizaje profundo y capaz de realizar una amplia gama de tareas de procesamiento de lenguaje natural (NLP), como el análisis de sentimientos, la respuesta a preguntas conversacionales, la traducción de textos, la clasificación y la generación. Un LLM es un tipo de red neuronal (NN) que utiliza específicamente arquitecturas de transformadores, que son modelos diseñados para detectar dependencias entre diferentes partes de una secuencia de datos, independientemente de su distancia entre sí. Estas redes neuronales están compuestas por capas de unidades de procesamiento, frecuentemente comparadas con las neuronas del cerebro. Los modelos de lenguaje grandes también tienen una gran cantidad de parámetros similares a las memorias que el modelo recopila a medida que aprende del entrenamiento. Piensa en estos parámetros como el banco de conocimientos del modelo.
Esta capacidad de procesamiento permite entrenar a los LLMs para tareas como escribir código de software, generación de lenguaje y más, mientras que los modelos especializados manejan tareas como comprender las estructuras de las proteínas.1 Los modelos de lenguaje grandes se deben ser preentrenar y luego ajustarlos para resolver problemas de clasificación de texto, respuestas a preguntas, resumenes de documentos, generación de texto, y otras tareas. Sus capacidades para resolver problemas se pueden aplicar a campos como la salud, las finanzas y el entretenimiento, donde los LLM sirven a una variedad de aplicaciones de PLN, como la traducción, los chatbots y los asistentes de IA.
Mira este video y conoce los LLM más a fondo.
¿Cómo funcionan los LLMs?
Básicamente, un modelo de lenguaje grande funciona al recibir una entrada, la codifica y luego, la decodifica para producir una predicción de salida, como la siguiente palabra, oración o una respuesta específica. Al igual que todos los modelos de machine learning, un modelo de lenguaje grande necesita un entrenamiento y ajuste antes de que esté listo para generar la salida de los resultados esperados y necesarios. Así es como se refina el proceso:
- Entrenamiento: los modelos de lenguaje grande se preentrenan al usar grandes conjuntos de datos textuales de sitios como Wikipedia y GitHub. Estos conjuntos de datos consisten en billones de palabras, y su calidad está destinada a afectar el rendimiento del modelo de lenguaje. En este punto, el modelo de lenguaje grande realiza un aprendizaje no supervisado, lo que significa que procesa los sets de datos que se le proporcionan sin instrucciones específicas. Durante este proceso, el algoritmo aprende a reconocer las relaciones estadísticas entre las palabras y su contexto. Por ejemplo, aprenderá a comprender si "right" significa "correcto" o lo opuesto de "left".
- Ajuste: para que un modelo de lenguaje grande realice una tarea específica, como la traducción, se debe ajustar a esa actividad en particular. El ajuste fino adapta los parámetros del modelo para optimizar su rendimiento en tareas específicas mediante el entrenamiento con datos etiquetados adicionales.
- El ajuste de indicaciones cumple una función similar al ajuste fino, mediante el cual se entrena a un modelo para llevar a cabo una operación mediante indicaciones de pocos ejemplos o de cero ejemplos. El método de pocas indicaciones proporciona al modelo ejemplos para guiarlo en la predicción de salidas, tales como:
| Reseña del cliente | Sentimiento del cliente |
|---|---|
| “¡Esta planta es tan hermosa!” | Positivo |
| ¡Esta planta es horrible! | Negativo |
En este caso, el modelo entiende el significado de "horrible" porque se proporcionó un ejemplo opuesto (hermoso).
Sin embargo, el método de zero-shot (cero disparos) no usa ejemplos. En su lugar, le pide directamente al modelo que realice una tarea, como:
"El sentimiento en 'Esta planta es horrible' es…"
En función del entrenamiento previo, el modelo debe predecir la opinión sin haber tenido ningún ejemplo.Componentes clave de modelos de lenguaje grandes
Los modelos de lenguaje grandes están compuestos de varias capas de redes neuronales. Las capas de incrustación, atención y avance trabajan juntas para procesar el texto de entrada y generar el contenido de salida.
- La capa de incrustación crea incrustaciones vectoriales. del texto de entrada o de las representaciones matemáticas de las palabras que se le introducen. Esta parte del modelo captura el significado semántico y sintáctico de la entrada para que el modelo pueda comprender contextualmente las palabras y sus relaciones.
- El mecanismo de atención permite que el modelo se enfoque en todas las partes del texto de entrada según su relevancia para la tarea actual, lo que le permite capturar dependencias a largo plazo.
- La capa de avance consta de varias capas totalmente conectadas que aplican transformaciones no lineales a los datos. Estos procesan la información después de haberse codificado por el mecanismo de atención.
Existen tres tipos principales de modelos de lenguaje grandes:
- Los modelos de lenguaje genéricos o sin procesar predicen la palabra siguiente según el lenguaje en los datos de entrenamiento. Estos modelos de lenguaje realizan tareas de recuperación de la información.
- Los modelos de lenguaje ajustados mediante instrucciones se entrenan para predecir respuestas a las instrucciones dadas en la entrada. Esto les permite realizar el análisis de sentimiento o generar texto o código.
- Los modelos de lenguaje ajustados mediante diálogo se entrenan para tener un diálogo mediante la predicción de la próxima respuesta. Piensa en los chatbots o en la IA conversacional.
¿Cuál es la diferencia entre los modelos de lenguaje grandes y la IA generativa?
IA generativa es un término general para los modelos de inteligencia artificial que pueden crear contenido. Estos modelos pueden generar texto, código, imágenes, video y música. También pueden especializarse en diferentes tipos de contenido, como la generación de texto (p. ej.: ChatGPT) o la creación de imágenes (p. ej.: DALL-E, MidJourney).
Los modelos de lenguaje grandes son un tipo de IA generativa que se entrenan específicamente en grandes conjuntos de datos textuales y están diseñados para producir contenido textual, como en el caso de ChatGPT.
Todos los LLM son IA generativa, pero no todos los modelos de IA generativa son LLMs. Por ejemplo, DALL-E y MidJourney generan imágenes, pero no texto.
¿Qué es un modelo de transformadores?
Un modelo de transformadores es la arquitectura más común de un modelo de lenguaje grande. Generalmente consta de un codificador y un decodificador, aunque algunos modelos, como GPT, usan solo el decodificador. Un modelo de transformadores procesa datos tokenizando la entrada, y luego, simultáneamente, realiza ecuaciones matemáticas para descubrir relaciones entre los tokens. Esto permite a la computadora ver los patrones que un humano vería si recibiera la misma consulta.
Los modelos de transformadores funcionan con mecanismos de autoatención, lo que permite que los modelos aprendan más rápido que los modelos tradicionales, como los modelos de memoria a corto plazo. La autoatención es lo que permite a los modelos de transformadores capturar las relaciones entre palabras, incluso las que están muy separadas en una oración, mejor que los modelos más antiguos, principalmente, al permitir el procesamiento paralelo de la información.
Relacionado: Aplica transformadores a tus aplicaciones de búsqueda
Ejemplos y casos de uso de modelos de lenguaje grandes
Los modelos de lenguaje grandes pueden usarse con varios fines:
- Recuperación de información: piensa en Bing o en Google. Los LLMs pueden integrarse en motores de búsqueda para mejorar las respuestas a las consultas. Mientras que los motores de búsqueda tradicionales se basan principalmente en algoritmos de indexación, los LLMs mejoran la capacidad de generar respuestas más conversacionales o contextuales basadas en una consulta.
- Análisis de sentimientos: como aplicaciones del procesamiento del lenguaje natural, los modelos de lenguaje grandes permiten a las empresas analizar el sentimiento de los datos textuales.
- Generación de texto: los modelos de lenguaje grandes como ChatGPT están detrás de los sistemas generativos de IA y pueden generar texto coherente y contextualmente relevante basado en indicaciones dadas. Por ejemplo, puedes dar una indicación a un LLM con "Escríbeme un poema sobre palmeras al estilo de Emily Dickinson".
- Generación de código: al igual que la generación de texto, los LLM pueden generar un código como una aplicación de IA generativa. Los LLMs pueden generar un código sintáctica y lógicamente correcto basado en indicaciones de entrada al aprender de grandes cantidades de código de programación en varios idiomas.
- Chatbots e IA conversacional: los modelos de lenguaje grandes potencian los chatbots de servicio al cliente y la IA conversacional. Ayudan a interpretar las consultas de los clientes, comprender la intención y generar respuestas que simulan una conversación humana.
Relacionado: Cómo hacer un chatbot: lo que deben hacer los desarrolladores y lo que no
Además de estos casos de uso, los modelos de lenguaje grandes pueden completar oraciones, responder preguntas y resumir texto.
Con una variedad tan amplia de aplicaciones, los LLMs se pueden encontrar en una gran variedad de campos:
- Tecnología: los modelos de lenguaje grandes se utilizan en diversas aplicaciones, como mejorar las respuestas de consulta de los motores de búsqueda y asistir a los desarrolladores en la escritura de código.
- **Salud y ciencia:** los modelos de lenguaje grandes pueden analizar datos textuales relacionados con proteínas, moléculas, ADN y ARN, asistiendo en la investigación, el desarrollo de vacunas, identificando posibles curas para enfermedades y mejorando los medicamentos de atención preventiva. Los LLM también se utilizan como chatbots médicos para la admisión de pacientes o diagnósticos básicos, aunque generalmente, requieren supervisión humana.
- Servicio al cliente: los LLMs se utilizan en todas las industrias para fines de servicio al cliente, como chatbots o IA conversacional.
- **Marketing:** los equipos de marketing pueden usar LLMs para crear un análisis de sentimientos, generar contenido e ideas de campañas de tormenta de ideas, ayudando a generar texto para lanzamientos, anuncios y otros materiales.
- Legal: desde la búsqueda en enormes sets de datos legales hasta la redacción de documentos legales, los modelos de lenguaje grandes pueden ayudar a abogados, asistentes legales y personal jurídico.
- Banca: los LLMs pueden ayudar a analizar las transacciones financieras y las comunicaciones con los clientes para detectar posibles fraudes, a menudo, como parte de sistemas más amplios de detección de fraudes.
Da el primer paso con la IA generativa en el ámbito empresarial. Mira este webinar y explora los desafíos y oportunidades de la IA generativa en tu entorno empresarial.
Limitaciones y desafíos de los LLM
Los modelos de lenguaje grandes pueden darnos la impresión de que comprenden el significado y pueden responder con precisión. Sin embargo, siguen siendo una herramienta que se beneficia de la supervisión humana y enfrentan varios desafíos.
- **Alucinaciones:** una alucinación se produce cuando un LLM genera una salida que es falsa o que no coincide con la intención del usuario. Por ejemplo, alega ser humano, que tiene emociones o que está enamorado del usuario. Debido a que los modelos de lenguaje grandes predicen la siguiente palabra o frase sintácticamente correcta, pero no pueden interpretar completamente el significado humano, el resultado a veces puede ser lo que se conoce como una "alucinación".
- Seguridad: los modelos de lenguaje grandes presentan riesgos de seguridad significativos cuando no se gestionan o monitorizan adecuadamente. Podrían filtrar inadvertidamente información privada de los datos de entrenamiento o durante las interacciones y podrían explotarse con fines maliciosos, como phishing o generando spam. Los usuarios con intenciones maliciosas también pueden explotar los LLM para propagar ideologías sesgadas, información errónea o contenido malicioso.
- **Sesgo:** los datos usados para entrenar modelos de lenguaje afectarán las salidas que produce un modelo dado. Si los datos de entrenamiento carecen de diversidad o están sesgados hacia un grupo demográfico específico, el modelo puede reproducir estos sesgos, lo que resulta en salidas que reflejan una perspectiva sesgada y probablemente limitada. Es clave garantizar un conjunto de datos de entrenamiento diverso y representativo para reducir el sesgo en las salidas del modelo.
- **Consentimiento:** los modelos de lenguaje grandes se entrenan en conjuntos de datos masivos, algunos de los cuales pueden haberse recopilado sin consentimiento explícito o sin adherirse a los acuerdos de derechos de autor. Esto puede resultar en violaciones de los derechos de propiedad intelectual, donde el contenido se reproduce sin la atribución o el permiso adecuados. Además, estos modelos pueden raspar datos personales, lo que plantea problemas de privacidad.2 Hubo casos en los que los LLMs han enfrentado desafíos legales, como demandas de empresas como Getty Images3 por infracción de derechos de autor.
- Escalado: el escalado de los LLMs puede ser muy intensivo en recursos, que requieren una potencia computacional significativa. Mantener dichos modelos implica realizar actualizaciones, optimizaciones y monitoreos continuos, lo que lo convierte en un proceso que consume mucho tiempo y recursos. La infraestructura necesaria para soportar estos modelos también es sustancial.
- Despliegue: desplegar modelos de lenguaje grandes requiere experiencia en aprendizaje profundo y arquitecturas de transformadores, junto con hardware especializado y sistemas de software distribuidos.
Beneficios de los LLMs
Con un amplio rango de aplicaciones, los modelos de lenguaje grandes son excepcionalmente beneficiosos para la solución de problemas, dado que brindan información en un estilo claro y conversacional que es fácil de comprender para los usuarios.
- Tienen una amplia gama de aplicaciones: puedes usarlas para la traducción de idiomas, la completación de oraciones, el análisis de sentimientos, la respuesta a preguntas, la resolución de ecuaciones matemáticas, y más.
- Siempre mejorando: el rendimiento de los modelos de lenguaje grandes mejora continuamente a medida que se integran datos y parámetros adicionales. Esta mejora también depende de factores como la arquitectura del modelo y la calidad de los datos de entrenamiento agregados. En otras palabras, cuanto más aprende un modelo, mejor se vuelve. Además, los modelos de lenguaje grandes pueden exhibir lo que se llama "aprendizaje en contexto", donde el modelo puede realizar tareas basadas en los ejemplos proporcionados en el mensaje, sin necesidad de entrenamiento o de parámetros adicionales. Esto permite que el modelo generalice y se adapte a varias tareas a partir de pocos ejemplos (aprendizaje de pocos disparos) o incluso sin ejemplos previos (aprendizaje de cero disparos). De este modo, aprende continuamente.
- Aprenden rápido: con el aprendizaje en contexto, los LLM pueden adaptarse a nuevas tareas con ejemplos mínimos. Aunque no necesitan entrenamiento ni parámetros adicionales, pueden responder rápidamente al contexto de la solicitud, lo que los hace eficaces en escenarios donde se les agrega pocos ejemplos.
Ejemplos de modelos de lenguaje grandes populares
Los modelos de lenguaje grandes populares han conquistado el mundo. Muchos han sido adoptados por personas en todas las industrias. Sin dudas has oído hablar de ChatGPT, una forma de chatbot de IA generativa.
Otros modelos de LLM populares son los siguientes:
- PaLM: el Pathways Language Model (PaLM) de Google es un modelo de lenguaje de transformadores capaz de realizar razonamientos aritméticos y de sentido común, explicar bromas, generar código y traducir.
- BERT: el modelo de lenguaje Representaciones de Codificador Bidireccional de Transformadores (BERT) también se desarrolló en Google. Es un modelo basado en transformadores que puede comprender el lenguaje natural y responder preguntas.
- XLNet: es un modelo de lenguaje de permutación que entrena en todas las permutaciones posibles de tokens de entrada, pero genera predicciones de una manera estándar de izquierda a derecha durante la inferencia.
- GPT: los transformadores generativos preentrenados son quizá los modelos de lenguaje grandes más conocidos. Desarrollado por OpenAI, GPT es un modelo fundacional popular cuyas iteraciones numeradas son mejoras de sus predecesores (GPT-3, GPT-4, etc.). Los modelos GPT se pueden ajustar para tareas específicas. Por separado, otras organizaciones han desarrollado modelos específicos de dominio inspirados en los LLMs fundamentales, como EinsteinGPT de Salesforce para aplicaciones CRM y BloombergGPT para datos financieros.
Relacionado: Guía de inicio para LLMs de código abierto
Futuros avances en los modelos de lenguaje grandes
La llegada de ChatGPT ha llevado a los modelos de lenguaje grandes al primer plano y activó la especulación y el debate acalorado sobre cómo podría verse el futuro.
A medida que los modelos de lenguaje grandes continúan creciendo y mejorando su manejo del lenguaje natural, hay mucha inquietud respecto al impacto de sus avances en el mercado laboral.
En las manos adecuadas, los modelos de lenguaje grandes pueden aumentar la productividad y la eficiencia de los procesos, pero esto ha planteado cuestiones éticas sobre su uso en la sociedad humana.
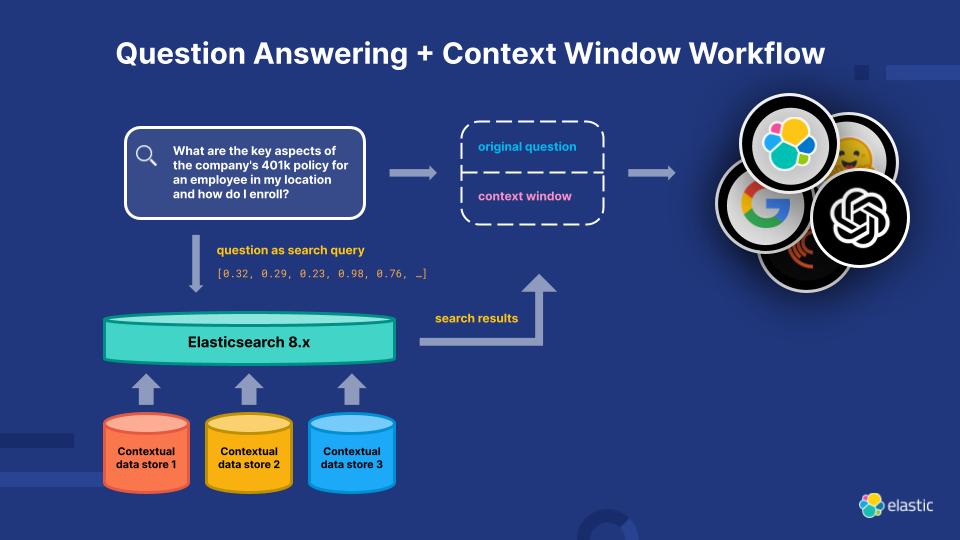
Conociendo el motor de relevancia de Elasticsearch
Para abordar las limitaciones actuales de los LLM, Elasticsearch Relevance Engine (ESRE) es un motor de relevancia creado para aplicaciones de búsqueda impulsadas por inteligencia artificial. Con ESRE, los desarrolladores están facultados para crear su propia aplicación de búsqueda semántica, utilizar sus propios modelos de transformadores y combinar NLP y AI generativa para mejorar la experiencia de búsqueda de sus clientes.
Potencia tu relevancia con Elasticsearch Relevance Engine
Explora más recursos de modelos de lenguaje grandes
- Observabilidad de LLM
- Herramientas y capacidades de IA generativa de Elastic
- Cómo elegir una base de datos vectorial
- Cómo hacer un chatbot: lo que deben y no deben hacer los desarrolladores
- Elegir un LLM: la guía de primeros pasos con los LLMs de código abierto
- Modelos de lenguaje en Elasticsearch
- Tendencias tecnológicas para 2025: cómo aprovechar la era de las opciones para llevar la GenAI a la producción
- Visión general del procesamiento de lenguaje natural (NLP) en el Elastic Stack
- Modelos de terceros compatibles con el Elastic Stack
- Guía de modelos entrenados en el Elastic Stack
- Evaluación de seguridad del LLM
Notas al pie
- Sarumi, Oluwafemi A. y Dominik Heider. Modelos de lenguaje grandes y sus aplicaciones en bioinformática ("Large Language Models and Their Applications in Bioinformatics"). Revista de Biotecnología Computacional y Estructural, vol. 23, abril de 2024, pp. 3498–3505.
https://www.csbj.org/article/S2001-0370(24)00320-9/fulltext. - Sheng, Ellen. "En el salvaje oeste legal de la IA generativa, las batallas judiciales recién están comenzando", CNBC, 3 de abril de 2023, https://www.cnbc.com/2023/04/03/in-generative-ai-legal-wild-west-lawsuits-are-just-getting-started.html (último acceso el 29 de junio de 2023).
- Declaración de Getty Images, Getty Images, 17 de enero de 2023 https://newsroom.gettyimages.com/en/getty-images/getty-images-statement (Último acceso el 29 de junio de 2023).