Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
When designing semantic search engines, RAG applications, or any other system that uses embeddings, one decision can make or break your search quality: how to chunk your data.
Chunking is the process of breaking down large texts into smaller, semantically meaningful pieces that can be individually embedded and searched. It becomes necessary when you're working with documents longer than your embedding model's context window, or when you need to retrieve specific, relevant passages rather than entire documents. While traditional text search indexes documents as-is, vector-based systems need a different approach for two main reasons:
- Embedding models have a token limit that restricts how much text can be processed at once. For example, the limit for ELSER and e5-small is 512 tokens. To generate meaningful embeddings, we need to divide texts; otherwise, any information contained in tokens beyond the limit is lost.
- LLMs also have a token limit, and their attention is limited as well; therefore, it is much more efficient to send only relevant chunks rather than a whole document. Chunking yields better results and makes it harder to exceed the token limit.
Keep in mind that the specific embedding model you choose has major implications for your chunking strategy:
- Models with larger context windows allow for bigger chunks that preserve more context, while smaller context models require more aggressive chunking.
- Some models are optimized for shorter passages, while others work better with paragraphs.
In this blog, we will discuss the fundamentals of chunking and explore how using chunking strategies affects semantic search results in Elasticsearch.
What is chunking?
Chunking is the process of breaking large documents into smaller pieces (typically) before creating embeddings and indexing them. Instead of having a 50-page text converted into a single embedding, chunking splits it into smaller logical units that can be searched over individually.
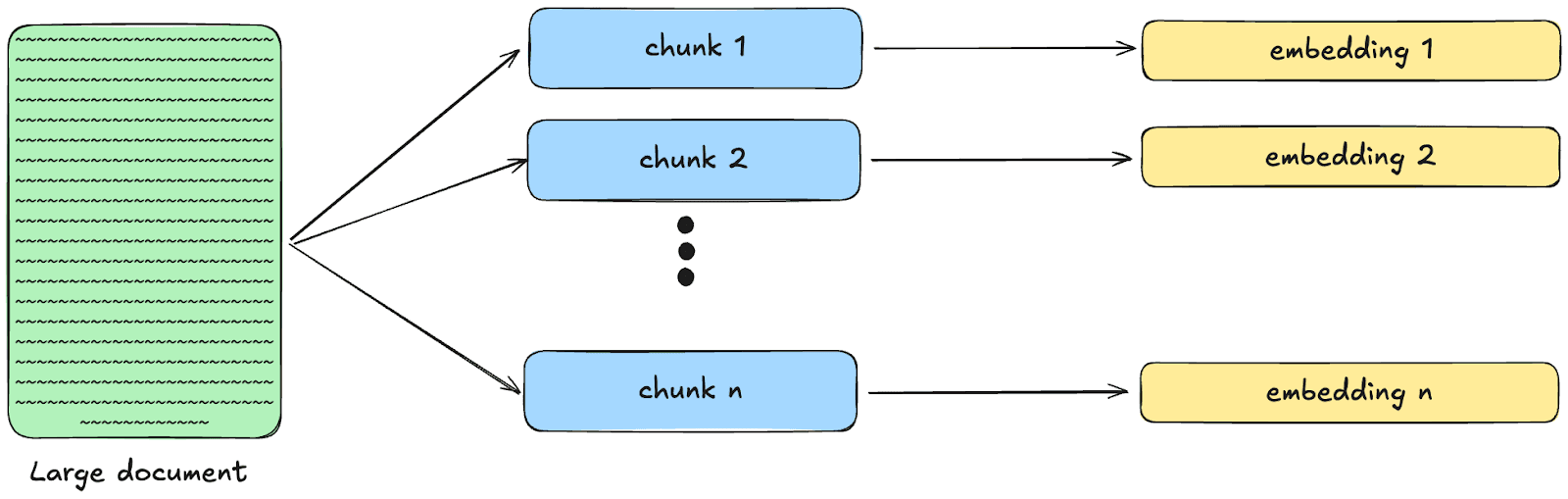
In Elasticsearch, the semantic_text field type uses chunking to break down texts into smaller pieces before automatically generating the embeddings.
Why does chunking matter for search quality?
If we do not apply chunking before generating embeddings, we can encounter some problems, such as:
- LLM context window and attention limitations: LLMs have a limited number of tokens they can take as a context. If we feed all the text just for a small part with relevant context, we will reach this limit more easily. Additionally, even if the text fits within the context window, LLMs suffer from attention problems such as “lost in the middle” problems, where important information is overlooked in large blocks of text.
- Embedding quality and data loss: An embedding from a large document might fail to capture a single concept well, being too general and diluted. Smaller chunks translate to more focused embeddings that better represent the information. On the other hand, if the text exceeds the token limits of the model, information is simply lost, as it is not taken into account when generating the embedding.
- Results readability: Chunking will produce results that are easy to read by humans. Instead of having to read the whole document, you can retrieve relevant sections only.
Relationship between chunk size and search precision
The size of each chunk creates a trade-off in vector search:
- Smaller chunks: Will provide more precise matches, but they might lack a meaningful context for the information to be understood.
- Larger chunks: Will have more context but might include multiple concepts, resulting in a less precise match.
The goal is to select a chunk size so that the information is minimized while still containing useful context. As a general guide, we can think of the size like this:
Smaller chunks:
- When you need highly specific, factual answers (like looking up definitions, dates, or specific procedures)
- When your documents contain many distinct, self-contained concepts
Larger chunks:
- When context is crucial for understanding (like analyzing arguments, narratives, or complex explanations)
- For documents in which concepts build upon each other and breaking them apart would cause a loss of meaning
To find the right chunk size for your use case, you can test with your own content. Monitor whether you're getting too many irrelevant results (chunks are too large) or answers that lack sufficient context (chunks are too small).
Chunking strategies
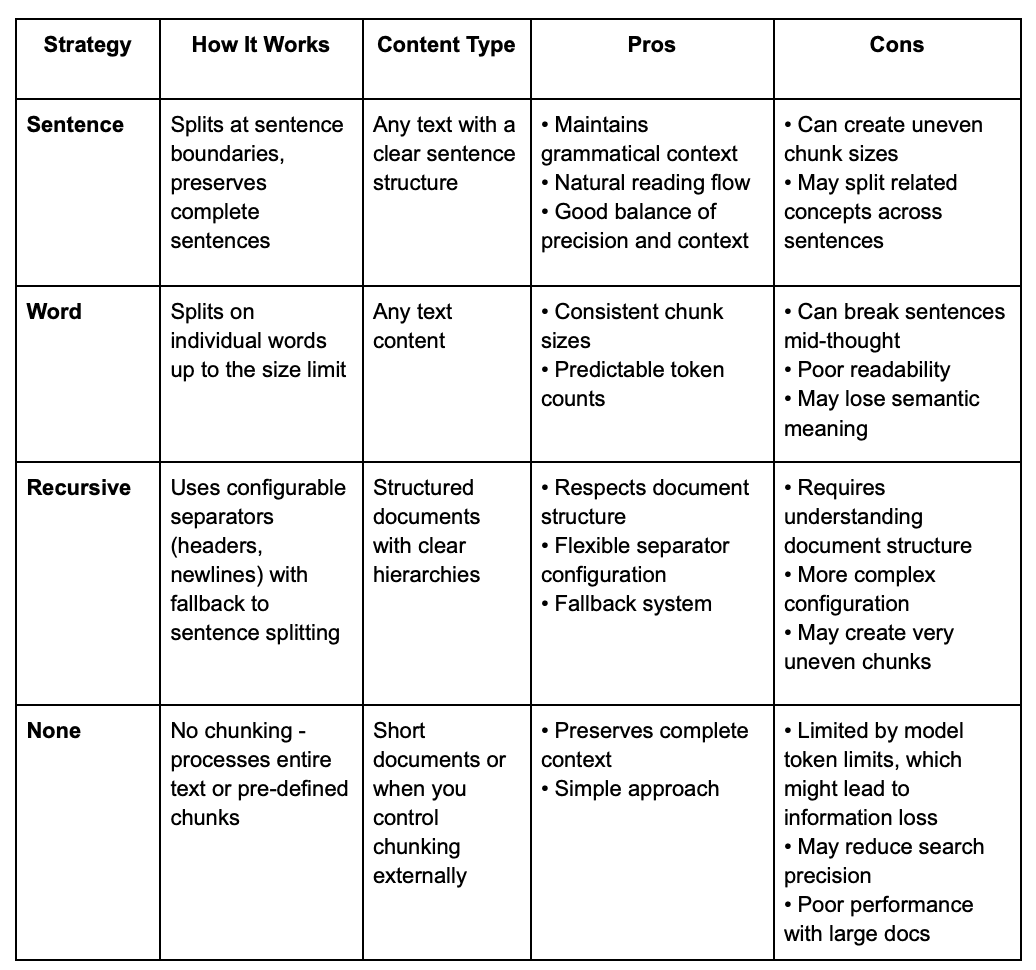
Elasticsearch allows us to choose different approaches for splitting documents. You can use this comparison table to select the most appropriate strategy for your use case, considering your document structure and the model you are using:
Now let’s see each strategy in action:
Sentence chunking
This strategy splits text into one or more complete sentences to prioritize readability and semantic coherence at the sentence level.
Input:
Result array (max_chunk_size: 50, sentence_overlap: 1):
Word chunking
This strategy splits the text into individual words up to the max_chunk_size. This ensures consistency in chunk sizes, providing predictability for processing and storage. The downside is that it might split relevant context across multiple chunks.
Input:
Result array (max_chunk_size: 25, overlap: 5):
Recursive chunking
This strategy splits the text based on a list of separators, such as newlines. It applies the separators in order and recursively. If after applying all the separators the chunks are still too large, it falls back to sentence splitting. This strategy is especially effective for formatted content (such as markdown documents).
Input:
Result array (max_chunk_size: 30, separators: ["#", "\n\n"]):
None
This “strategy” disables chunking and creates an embedding from the complete text. It is useful for smaller texts and documents where all the context is always needed. A potential pitfall of this strategy is that the model might discard excess tokens when generating the embedding.
Input:
Result:
Key Chunking Parameters
Elastic offers these customization parameters for the chunking strategy:
- overlap: Number of overlapping words between chunks. Used only in a word strategy.
- sentence_overlap: Number of overlapping sentences between chunks. Used only in a sentence strategy.
- separator_group: The predefined list of separators for the recursive chunk strategy. It can be “markdown” or “plaintext.”
- separators: A custom list of separators for the recursive chunking strategy. It can be a plain string or a regex pattern.
- strategy: The chosen strategy (sentence, word, recursive, or none).
- max_chunk_size: The maximum size of a chunk measured in words.
Chunking in Elasticsearch
Let's see how chunking works in Elasticsearch by walking through a practical example.
Chunking settings are specified when creating an inference endpoint, and Elasticsearch automatically handles the chunking process when you index documents.
In the following example, we will create a text_embedding inference endpoint with a sentence chunking strategy and check how chunks are generated and found in a semantic query:
1. Create the inference endpoint:
Here, we're using a maximum chunk size of 40 words without an overlap between chunks. The sentence strategy will split text at natural sentence boundaries.
Make sure you have the multilingual e5 small model deployed. This model has a maximum token window of 512.
2. Create an index with a semantic_text field that uses our new inference endpoint:
When you index a document, Elasticsearch automatically applies the chunking strategy and creates embeddings for each chunk in the my-semantic-field field.
3. Index a sample document into our index:
This document will be automatically split into multiple chunks based on our sentence strategy.
4. Perform a semantic search on the index:
Let’s take a look at the query part by part:
Here, we are asking to get the title and the inference fields back; these fields include information about the endpoint, the model, and the chunks.
This is the semantic query on my-semantic-field, it automatically uses the inference endpoint we created in step 1 to search for matches with the terms in the user_query.
This part will bring back the top hit of the chunks generated from the text.
Now the response:
Let’s break down the response:
Original content:
The complete original text that was indexed.
Chunking details:
This shows you:
- start_offset/end_offset: Character positions where each chunk begins and ends in the original text
- embeddings: The vector representation of each chunk (384 dimensions for the e5-small model)
- Number of chunks: In this case, 4 chunks were created from our coffee brewing text
Best matching chunk:
The highlight shows which specific chunk scored highest for our "how much time should I brew my coffee for?" query, demonstrating how semantic search found the most relevant content even when the exact words don't match.
Chunking strategies experiment
Setup
We will use the Wikipedia page for some countries in the Americas. These pages contain long texts, which allows us to demonstrate the difference between chunking and no-chunking strategies. We prepared a repository to get the Wikipedia content, and create the appropriate inference endpoints and mapping to upload the data.
1. Clone the repository:
2. Install required libraries:
3. Set up environment variables:
4. Run the set_up.py file:
This script executes these steps:
- Creates two inference endpoints, both using the ELSER model to generate sparse embeddings:
- sentence-chunking-demo: Uses a sentence chunking strategy with a max chunk size of 80 and a sentence overlap of 1
- none-chunking-demo: Does not use any chunking strategy
- It creates a mapping for the index countries_wiki, including two multifields for the wiki_article field:
- wiki_article.sentence: using the sentence-chunking-demo inference endpoint
- wiki_article.none: using the none-chunking-demo inference endpoint
- It gets the Wikipedia article for each country and uploads the title and content to our new index in the country and wiki_article fields, respectively
This might take several minutes; remember, Elastic is chunking and generating embeddings on the semantic text fields. If everything goes well, you will see the process finish correctly:
Run the semantic searches
The script run_semantic_search.py implements several helper functions to perform the same semantic search on both semantic text fields and prints the results in tables for easier comparison. You can simply execute the script like this:
You will see the results of each query defined in the demo_queries list (add your own queries here to test):
Results
Let’s explore a couple of results from the queries in the demo:
Query: countries in the inca empire
Strategy: sentence chunking

We get the expected results: Peru, Ecuador, Bolivia, Chile, Argentina, and relevant chunks. For example, for Argentina, we get a very specific piece of information:
As we can see, we can easily pinpoint why each document appeared in the results.
Query: countries in the inca empire
Strategy: no chunking

Here we can see the same results for the top 4, but at the end we see Mexico, which was not part of the Incan Empire in any way. We can also see that the whole document is received as one relevant chunk, so we can’t really tell why any of these documents were relevant. The problem with these results is that the embedding was formed from the first 512 tokens of the text, so a lot of information was lost. Most likely, we are not getting any information about the history of each country.
Query: hockey
Strategy: sentence chunking

We can see countries that are immediately related to hockey, like the USA and Canada, and also Argentina, Chile and Panama. In the relevant chunks column, we see how hockey is mentioned in each article.
Query: hockey
Strategy: no chunking

In these results, we can see countries that are not usually related to hockey (or winter sports in general). Since the relevant text is the whole article, we can’t really see why any of these appear in the results. Also, notice that the scores are much lower than before; this indicates that these might not be good results at all, these are just the “closest” to the query, but barely related.
Conclusion
As we can see, the use of a chunking strategy can drive the quality of the results. Without chunking, we end up with problems such as:
- Unrelated results (like Mexico in the Incan Empire): when the text is bigger than the token limit for our embedding model, some data is simply not included when generating the embedding, and we lose information.
- Results explanation: Even when results are relevant, it is much more difficult to explain why a particular document appeared from the whole text than from a relevant chunk. This can be a problem when verifying our results and building trust with our end users.
- Efficiency: If we are sending the results to an LLM downstream, whole documents quickly consume the context window with irrelevant information, leading to higher token costs and worse response quality.
All in all, a chunking strategy is always a good idea when dealing with texts longer than a model’s token limit. It improves results and reduces costs, making it a fundamental piece when designing AI systems.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.
June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.