Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
With the rise of large language models (LLMs), agent frameworks, and new protocols like Model Context Protocol (MCP), a provocative question is starting to surface:
Do we still need a search engine at all?
If agents can call tools on demand and models can reason over massive context windows, why not just fetch data live from every system and let the LLM figure it out?
It’s a reasonable question. It’s also the wrong conclusion.
The reality is that MCP and agent tooling don’t eliminate the need for search. They make the quality of search more critical than ever. In this blog, we’ll explore why MCP, federated search, and large context windows don’t replace search engines and why indexes remain the foundational layer for scalable, accurate, enterprise-grade AI.
What MCP actually is (and what it is not)
MCP is a coordination protocol. It standardizes how an agent requests information or actions from external systems.
What MCP doesn’t do:
- Rank results across systems.
- Understand relevance across heterogeneous data.
- Normalize schemas or metadata.
- Data transformations or enrichments at scale.
- Apply consistent security and permissions.
- Optimize for latency, cost, or scale.
In other words, MCP tells agents how to ask for data, not which data matters most.
Modern retrieval requires query intelligence, not just data access
In modern enterprise search architectures, retrieval quality is determined long before a query reaches an index. Raw queries — especially those generated by agents — may be incomplete, overly literal, schema-driven rather than intent-driven, and at times syntactically invalid.
This is why mature search platforms introduce a query intelligence layer that performs query rewriting, entity normalization, synonym expansion, and intent disambiguation before retrieval even begins.
For example, an agent-generated request such as: “Show severity 2 authentication failures from last sprint” may be rewritten to include authentication synonyms (login, SSO, OAuth), normalized severity mappings, and sprint-to-date-range translation. The result is not just more matches — it is more relevant matches.
In enterprise AI, retrieval is not a single step. It is a controlled pipeline.
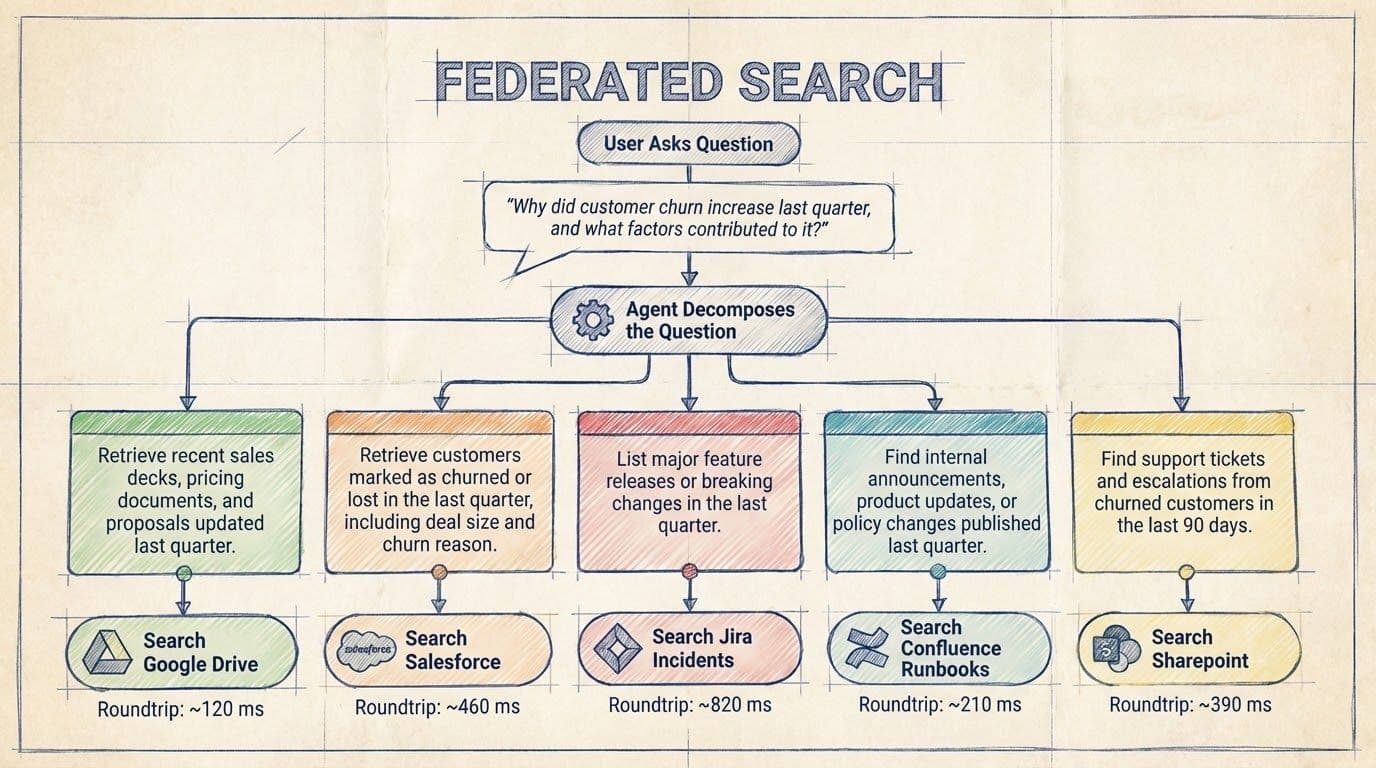
This distinction is crucial because once MCP-based agents start pulling information live from multiple tools, they recreate a familiar pattern under a new name: federated search.
MCP-based retrieval is federated search in disguise
Federated search isn’t new. Enterprises have tried it for decades.
The model is simple:
- Send the user’s query to multiple systems in parallel (SharePoint, GitHub, Jira, customer relationship management [CRM]).
- Collect the responses.
- Merge and present the results.
MCP-driven tool calls follow the same pattern, except that the caller is now an agent instead of a user interface.
And the same problems resurface.
Why federated search breaks down at enterprise scale
- Latency becomes unpredictable: A federated query is only as fast as its slowest system. Enterprise systems can have wildly different response times and rate limits, so federated queries tend to be slow and jittery. Agents must wait for multiple round trips before reasoning can even begin. The result is a laggy experience and unpredictable wait times.
- Relevance is fragmented: Because each system ranks results on its own, there’s no unified relevance model. Federated search cannot apply a single ranking or semantic understanding across all content, so results often seem disjointed or incomplete. Agents may retrieve correct information but not the most useful information.
- Context is shallow and incomplete: Federated systems typically expose only what’s directly accessible through an API call.They rarely surface:
- Usage signals, like clicks, dwell time, recency of access, popularity, or authority.
- Relationships between documents across different systems to correlate the insights.
- Organizational knowledge beyond a single silo.
This strips agents of the broader context required for high-quality reasoning.
- Limited filtering and features: In a federated setup, you can only filter on fields that every system supports (the “lowest common denominator”). If one system doesn’t support a particular filter or facet, you lose that functionality entirely. This severely limits rich search features, like date ranges, categories, or tags.
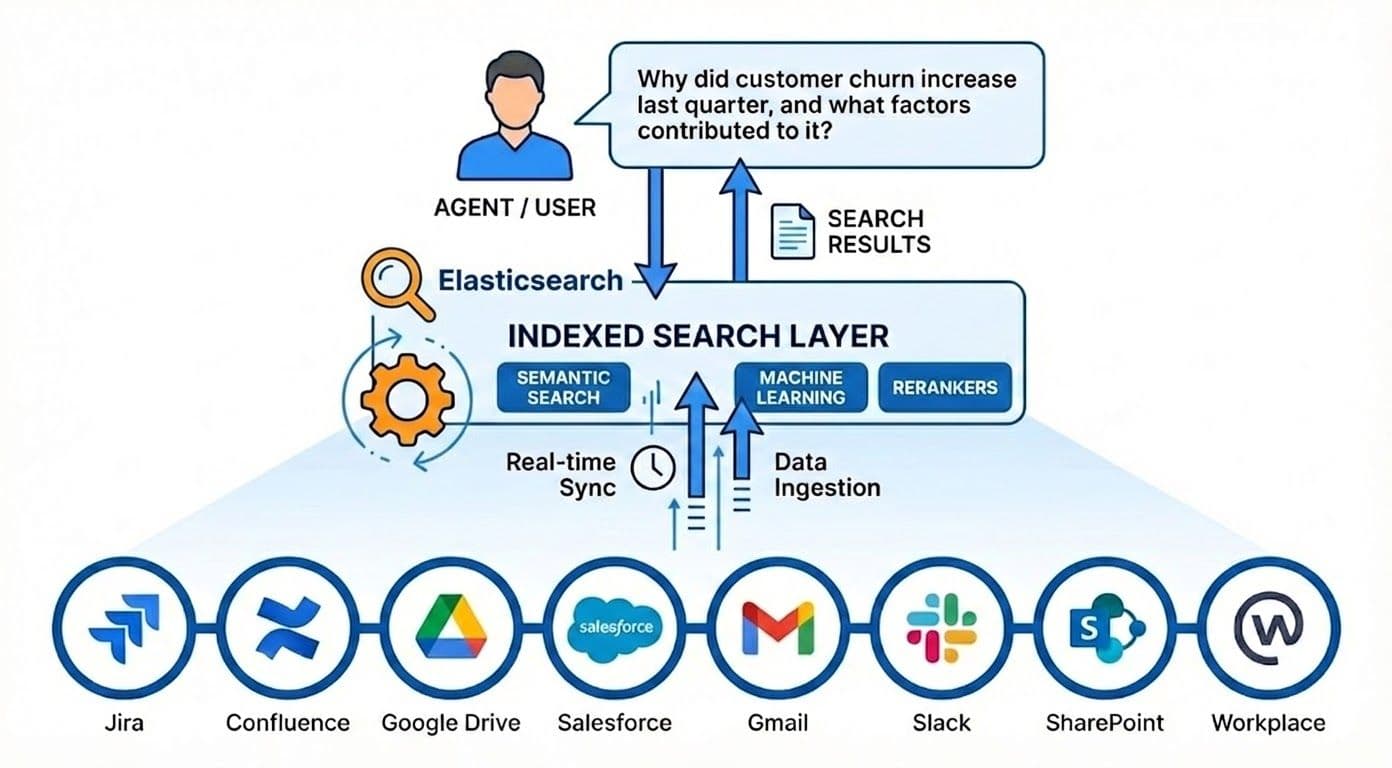
The power of an indexed search
Search engines achieve millisecond-level retrieval at massive scale by using specialized data structures, including inverted indexes for lexical search and k‑dimensional trees (k-d trees) for vector-based retrieval. The approach is to crawl or ingest every source into search engines, creating a central place of company knowledge. This brings big advantages:
- Speed by design: Searching an index is lightning fast. Queries hit inverted indexes and specialized data structures, avoiding the need to poll each backend system.
- Relevance that compounds over time: Search engines that support semantic search are capable of comprehending the intent, and machine learning models can rerank results for enterprise contexts. In one Elastic experiment, Elastic users see more accurate results when combining vector search with a question-answering (QA) model to extract answers. It gives better precision than keyword matching.
- Advanced features: Elastic’s Graph retrieval augmented generation (RAG) solution shows how structuring an index as a knowledge graph can power more contextual retrieval. In other words, indexes aren’t just backward-looking dumps of text; they can also encode relationships and ontologies that let AI connect the dots across documents.
- Permission-aware search: Enterprise AI cannot compromise on security. Indexed search allows:
Agents see only what users are allowed to see, without leaking data into model prompts or training. Elasticsearch is suitable for the indexed search layer in the diagram below, as it provides the essential components for context engineering.
Retrieval consistency through search templates and governed execution
At scale, retrieval must be predictable, secure, and repeatable. This is where search templates become critical.
Search templates act as retrieval contracts between applications, agents, and the search platform. Instead of dynamically constructing queries at runtime, agents invoke pre-defined retrieval patterns that enforce:
- Consistent relevance logic
- Mandatory security filters
- Cost and latency guardrails
- Business-specific ranking rules
- Explicit index and field scope boundaries
In MCP-driven architectures, this becomes even more important. Agents should not dynamically invent retrieval strategies. Instead, MCP tool calls can map directly to approved search templates, ensuring that every retrieval request adheres to enterprise relevance and governance standards.
This approach shifts retrieval from ad-hoc query execution to controlled retrieval orchestration.
Retrieval is now a multi-layer engineering discipline
Modern enterprise retrieval is no longer a simple query-to-index operation. It typically includes multiple coordinated layers:
- Query understanding — rewriting, expansion, entity resolution
- Retrieval strategy selection — hybrid search, vector search, graph retrieval, or synthetic query techniques such as Hypothetical Document Embeddings (HyDE), where the system generates a representative answer or expanded context first and retrieves documents using that richer semantic signal.
- Execution governance — templates, security enforcement, and performance guardrails
- Ranking and re-ranking — blending lexical precision, semantic similarity, and interaction-derived relevance signals such as click-through patterns, dwell time, and document usage frequency.
When these layers are implemented upstream, agents receive clean, high-confidence context rather than raw, fragmented data.
This is what makes large-scale agent systems reliable in production environments.
Advanced retrieval techniques improve context quality before reasoning begins
Modern retrieval systems increasingly use AI-assisted techniques to improve recall and semantic coverage before ranking is applied.
One example is Hypothetical Document Embeddings (HyDE). Instead of embedding only the original query, the system first generates a hypothetical answer or expanded context, embeds that representation, and retrieves documents based on that richer semantic signal.
This is particularly useful in enterprise environments where:
- Users or agents may not know the exact terminology
- Knowledge is distributed across silos
- Important context is implied rather than explicitly stated
Techniques like HyDE improve the probability that relevant documents are retrieved even when the original query is underspecified.
This reinforces a key principle of enterprise AI: better context retrieval produces better reasoning outcomes.
Agents aren’t data engineers; they’re reasoning systems
They shouldn’t be responsible for stitching together raw data, reconciling schemas, or compensating for poor retrieval.
This is where a search platform such as Elasticsearch becomes foundational.
By ingesting data once and normalizing it upstream (through pipelines, mappings, enrichment processors, and prebuilt indexes), Elasticsearch resolves schema mismatches, joins signals across sources, and materializes retrieval-ready views of the data. At query time, the agent receives clean, ranked, semantically enriched results rather than fragmented raw records.
For example, instead of an agent pulling independently from CRM, ticketing, and documentation systems and attempting to reconcile customer IDs, timestamps, and formats in real time, Elasticsearch can pre-index these sources into a unified customer interaction index with hybrid (keyword + vector) search and relevance ranking. The agent then queries a single, coherent interface and immediately reasons over the most relevant context.
This separation of concerns, that is, Elasticsearch handling data integration and retrieval, and agents focusing on reasoning, planning, and decision-making, is what makes agent systems scalable, reliable, and production ready.
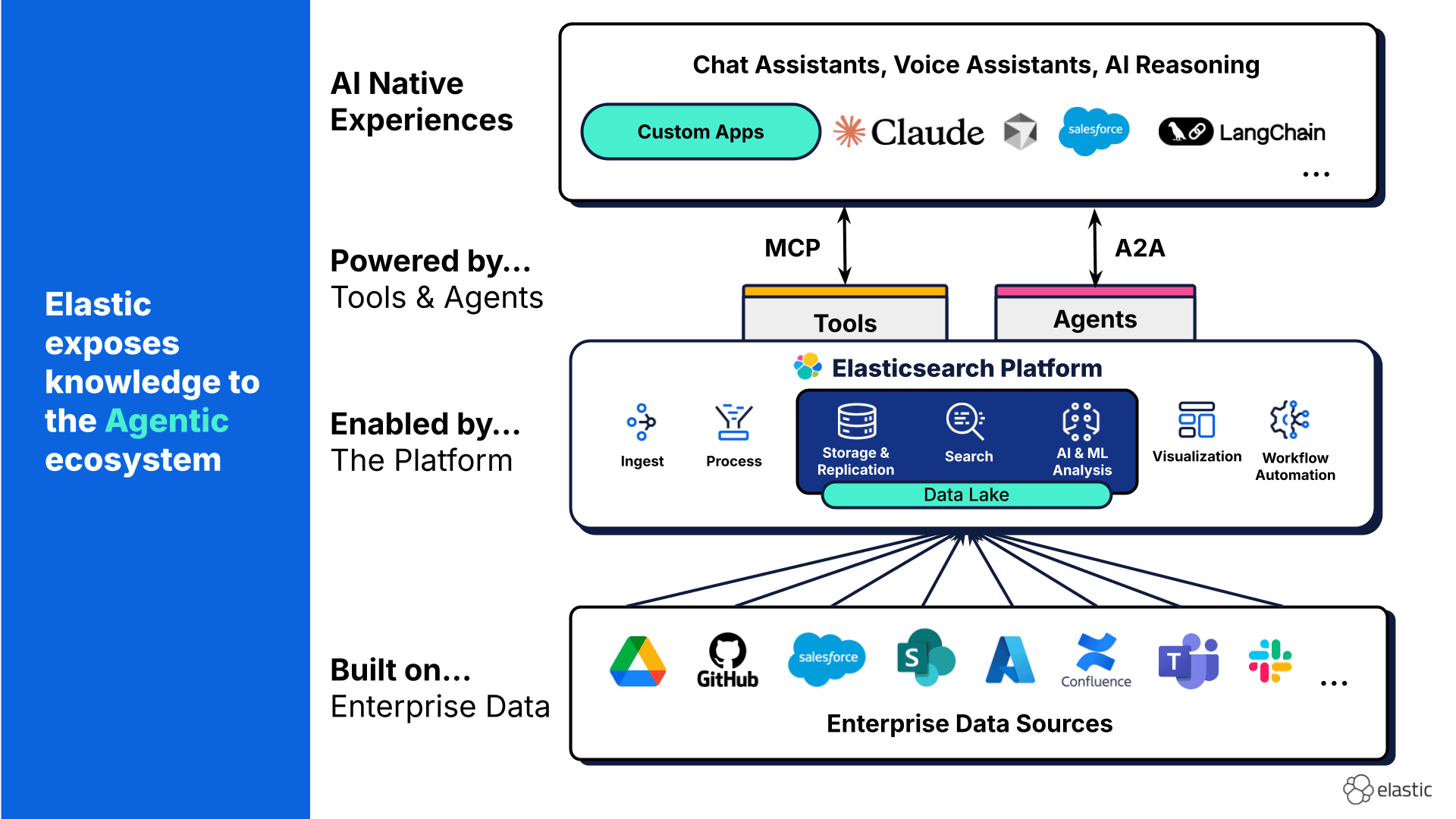
Elastic’s role in the AI stack
Elastic sits at the intersection of search and AI by design.
- Connectors and crawlers ingest data continuously from enterprise systems.
- Semantic and vector search enable intent-based retrieval.
- Hybrid search blends lexical precision with semantic understanding.
- RAG workflows ground LLMs in authoritative, permission-aware data.
Elastic does not compete with agents or MCP. It makes them effective.
Bigger models don’t eliminate retrieval
Some have wondered whether huge new LLMs can bypass traditional search, perhaps by letting the model read everything in one go. Large context windows feel powerful, but they introduce:
- Higher latency.
- Higher cost.
- Lower precision due to noise.
- A higher propensity for confusion, context clash, and context poisoning.
RAG wins because it filters first and then reasons.In another Elastic Search Labs experiment, RAG achieved answers in about 1 second, versus 45 seconds for the raw-LM approach, at 1/1250th the cost, and with far higher accuracy. In other words, giving an LLM a million tokens of documents is slower, more expensive, and actually less precise than filtering through an index first.
Conclusion: MCP changes the interface, not the fundamentals
MCP is a meaningful step forward in how agents interact with tools. But it doesn’t replace the need for fast, relevant, governed retrieval.
In enterprise AI:
- Context quality determines answer quality.
- Indexes create that context.
- Search is the foundation, not the legacy.
Indexes aren’t obsolete in the era of MCP. They’re the reason that MCP-based agents can work at all.
Related Content

July 20, 2026
AI shopping agents: Why context comes before the query
AI shopping agents that guess at your vocabulary make expensive mistakes. Pre-computed catalog context stops the guessing before the first tool call.

July 16, 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.

July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.