継続的なポーリングにより、KibanaのダッシュボードとDiscoverの読み込みが最大25%速くなりました。Kibanaは、定期的なチェックの合間にスリープする代わりに、HTTP接続を開いたままに維持し、準備ができたらすぐにElasticsearchのクエリ結果を配信するようになりました。HTTP/2+(9.0以降のKibanaのデフォルト)では、自動的に有効になるため、設定は不要です。HTTP/1では、Kibanaは接続プールの枯渇を防ぐために従来のポーリングに戻ります。
Kibanaがダッシュボードを読み込む際にデータを取得する方法
ダッシュボードを開くと、ほとんどのパネル(内部的には、これらを埋込と呼びます)が1つ以上のElasticsearchクエリを開始します。しかし、同期検索の単純な呼び出しと応答の代わりに、非同期検索のパワーを使います(ドキュメント)。
非同期検索では、クエリ結果が特定のHTTPリクエスト外でもElasticsearch内で利用可能な状態に保たれます。これが重要な理由を以下に挙げます。
- ネットワークの不安定性に耐性が高く、データの読み込みを安定させます
- バックグラウンド検索機能により、ユーザーは長時間実行されるダッシュボードやDiscoverセッションを待つ間も、Kibanaで他の作業を行うことができます
最初のクエリが送信された後、Kibanaは検索を監視して完了を検出し、結果のセットを取得します。
従来のポーリングがKibanaのダッシュボードのロード時間に与える影響
従来のポーリングでは、Kibanaはクエリを送信し、最初の接続を閉じてから、Elasticsearchの完了を定期的にチェックします。
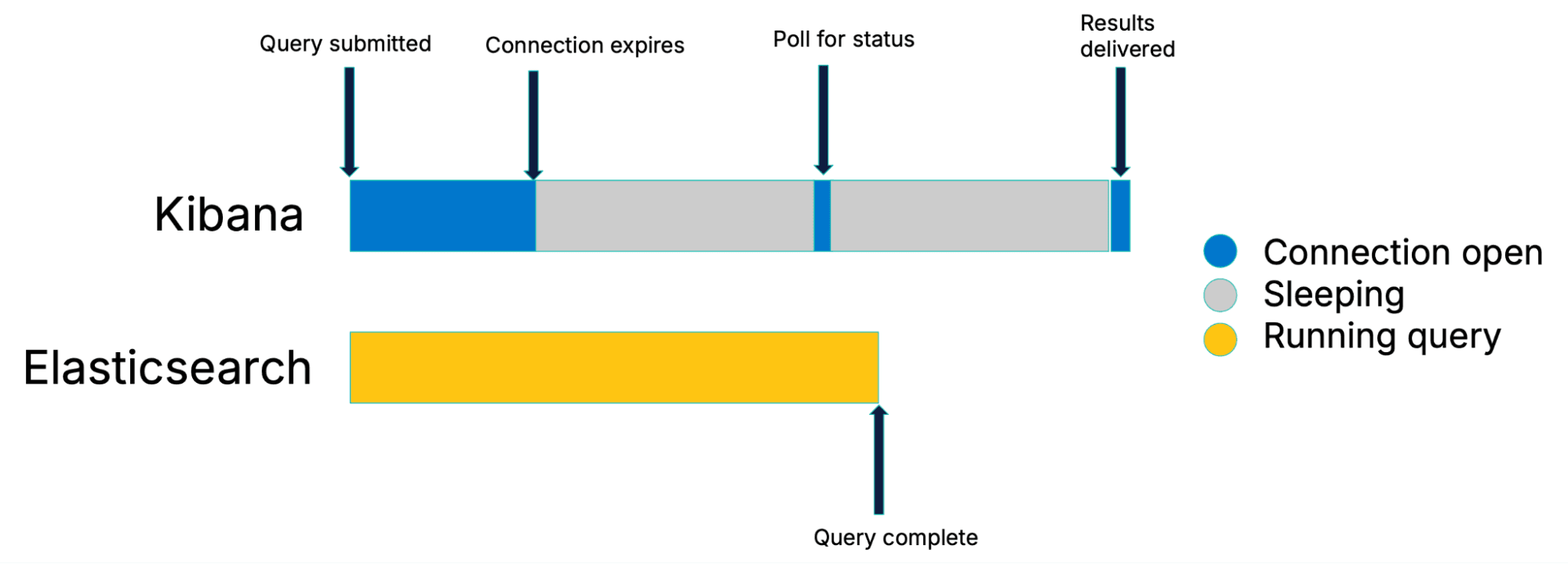
従来のポーリング戦略
Elasticsearchは、クエリ送信後に検索を完了して結果を返すまでの短い時間を設けています。もし検索がこれほど速く完了する場合、それは単純な呼び出しと応答のやり取りに相当します。しかし、長時間の検索の場合、最初の接続は切断され、Kibanaは検索の完了を定期的に確認し始めます。これはポーリングと呼ばれます。
従来のポーリングのパフォーマンス上の課題
上の図をご覧いただくと、このアプローチのパフォーマンス上の欠点がお分かりいただけるかもしれません。検索はKibanaのスリープインターバルのいずれかで終了する可能性が最も高く、そのため時間の無駄につながります。
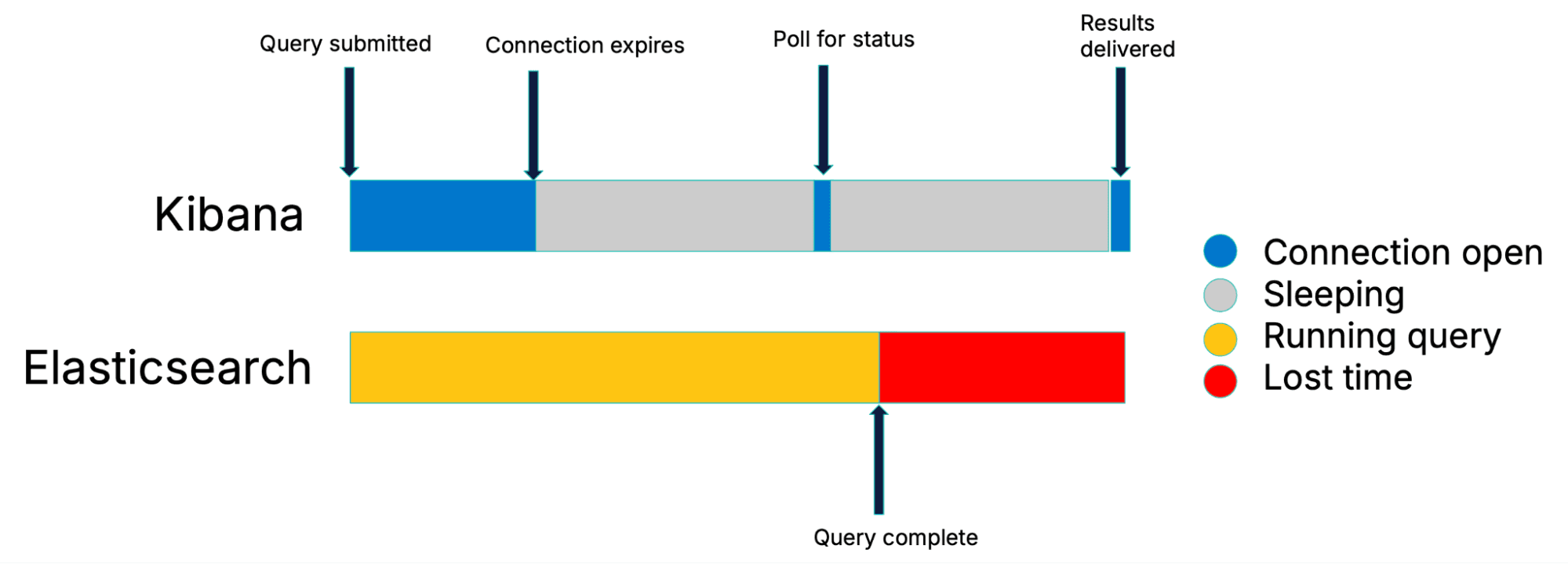
従来のポーリングの欠点
最悪のシナリオ(検索がスリープ期間の始めに完了する場合)では、ポーリングインターバルの全期間が無駄になります。
バックオフ戦略の影響
ポーリング時にはバックオフ戦略を適用するのが標準的な方法です。これは、検索の期間が長くなるほど、ポーリングの頻度が低くなることを意味します。
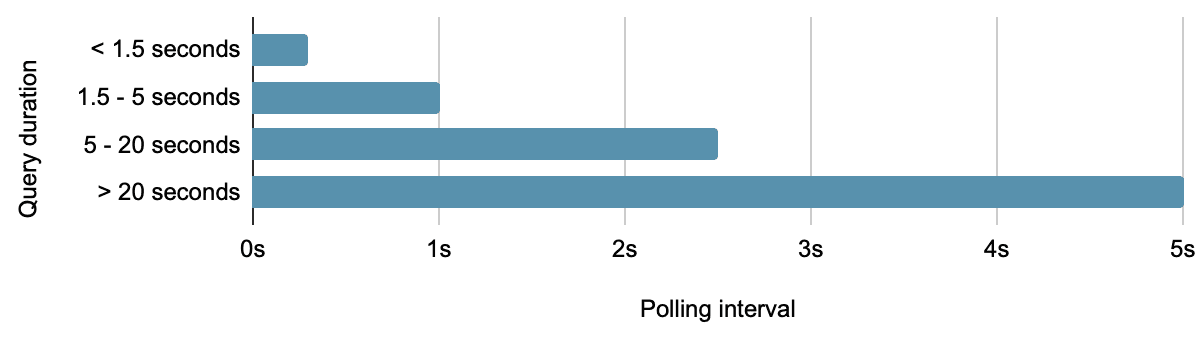
ポーリング間隔のバックオフスケジュール
しかし、これはまた、検索の期間に応じて潜在的な時間損失が比例して増加することを意味します。
ポーリング間隔がノコギリ状のレイテンシパターンを作り出す仕組み
これらの要素を合わせると、失われた時間は段階的なノコギリ状の関数となります。

クエリの実行時間によるタイムロス
ここで、ピークは最悪のシナリオ、谷は最良のシナリオを表しています。これは、従来のポーリングコストが、検索期間(およびネットワーク条件)に応じて、ゼロからポーリング間隔の全期間まで変化することを示しています。
継続的なポーリング:Kibanaが待ち時間を排除する仕組み
従来のポーリングの問題は、KibanaとElasticsearchの間にある根本的な連携不足です。理想は、Kibanaが結果が利用可能になったことを即座に認識することです。では、ほぼすべての時間をElasticsearchのチェックに費やし、待機時間をまったく設けないポーリングパターンに逆転させたらどうなるでしょうか?
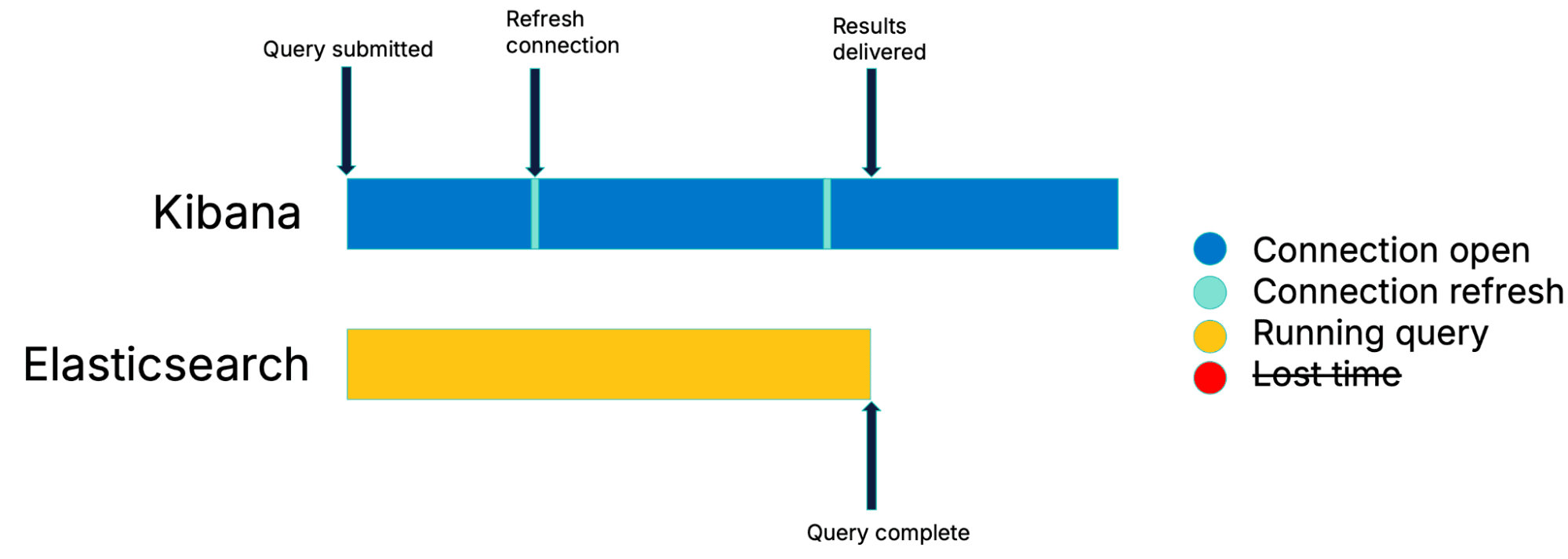
継続的ポーリング:タイムロスに対するソリューション
長時間のポーリングとスリープ期間の廃止を組み合わせることで、結果は準備ができ次第すぐに提供されます。
HTTP/1の陳腐化
その理論は堅実なものです。では、継続的なポーリングをオンにすると、なぜこのKibana導入はそれほど陳腐化して見えるのでしょうか?
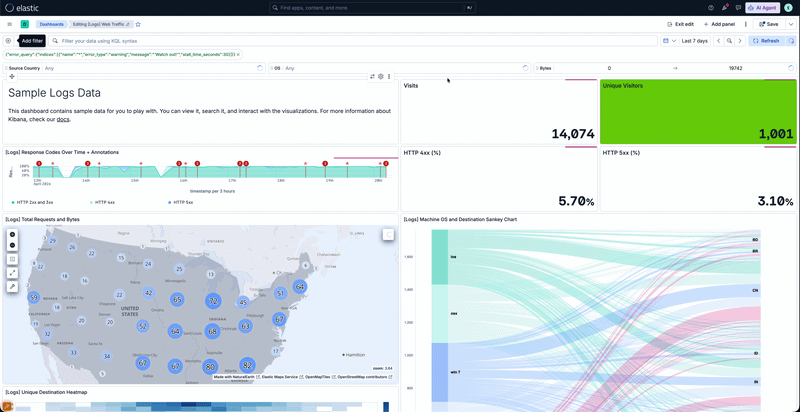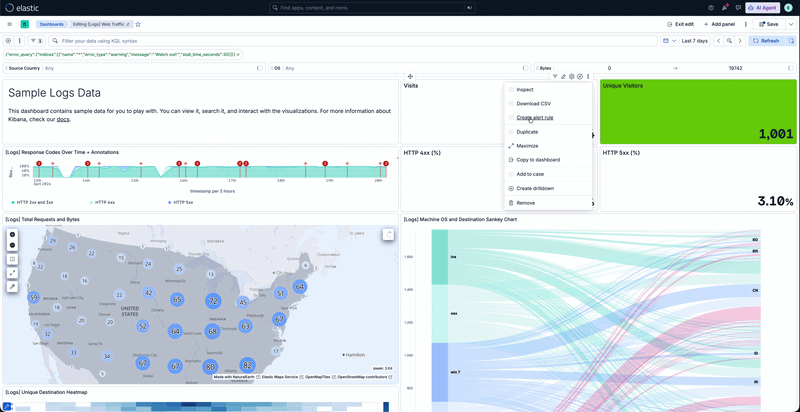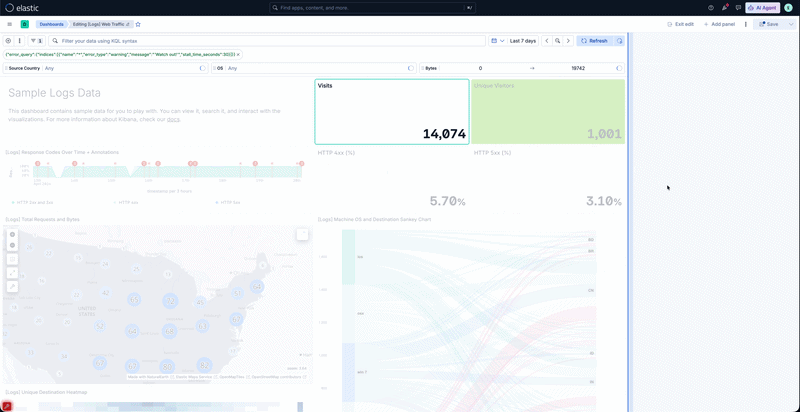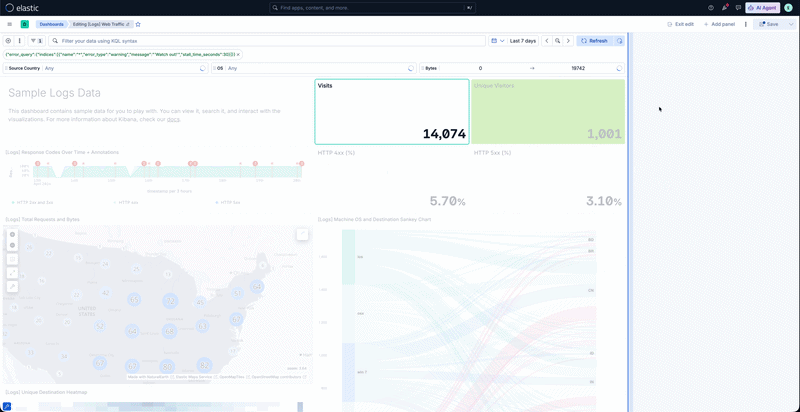
継続的ポーリングは、HTTP/1で接続しているクライアントのパフォーマンス低下を招きます。
重要なのは、この導入がHTTP/1上で実行されていることです。HTTP/1では、HTTPリクエストはTCP接続に1:1でマップされます。そのため、複数の長時間にわたるポーリングリクエストがブラウザの限られた接続プールを占有し、他のリクエストがキューに溜まってしまいます。
一方、HTTP/2+では、ネットワークリクエストは多重化によってTCP接続を共有できるため、この問題は発生しません。
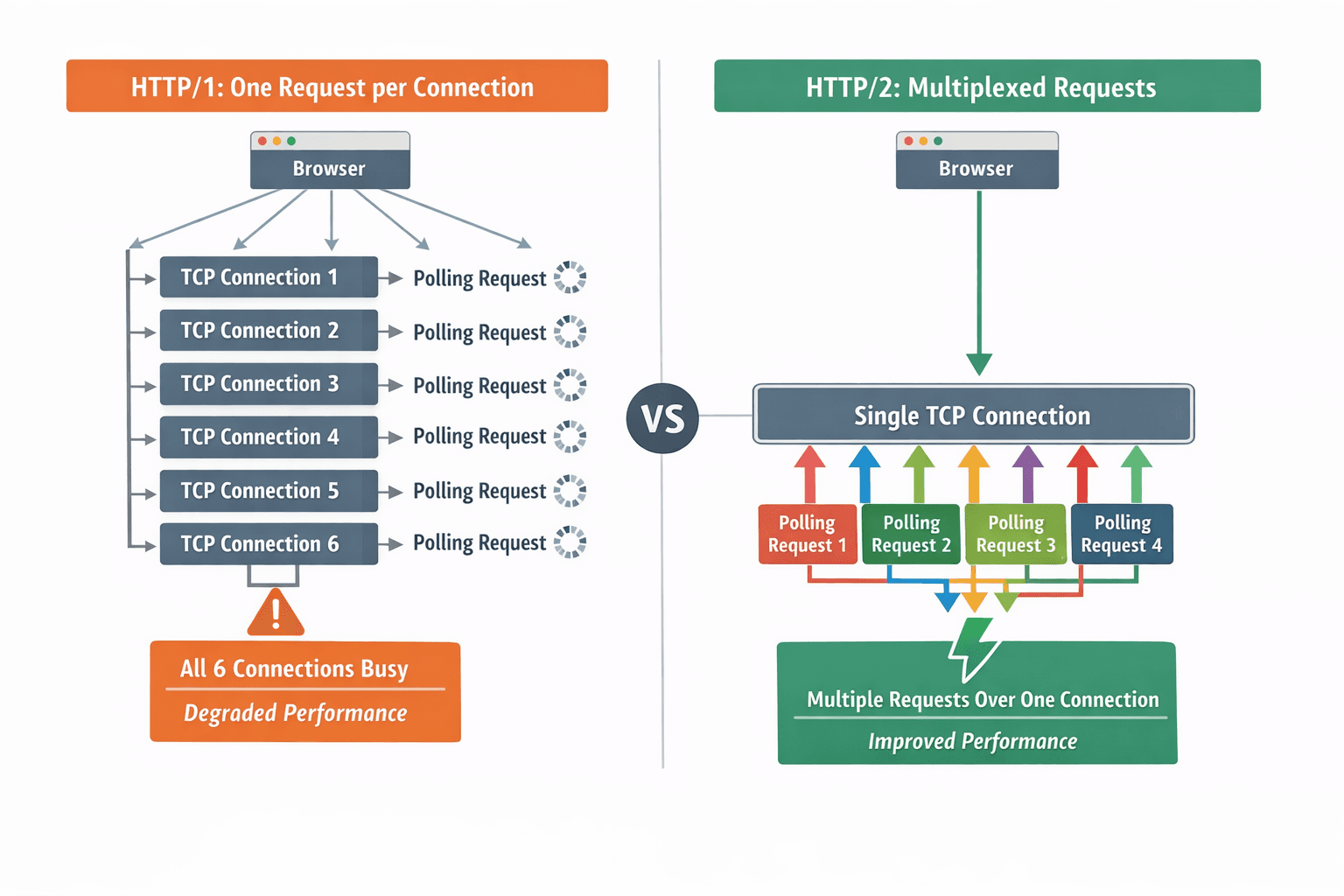
HTTP/1とHTTP/2+間のHTTP-TCPマッピングの違い
つまり、HTTP/2+では継続的なポーリングは利点となりますが、HTTP/1では欠点となります。
| HTTP/1 | HTTP/2+ | |
|---|---|---|
| TCP接続 | HTTPリクエストごとに1つ | 多重化(多くのリクエストが接続を共有) |
| 継続的なポーリング実行 | パフォーマンスが低下(接続プールの枯渇) | 最大の効果(結果をすぐに表示) |
KibanaがHTTPプロトコルを検出して最適なポーリングを行う方法
HTTP/2は推奨されているプロトコルであり、Kibanaのデフォルトは9.0以降であるため、このパフォーマンス向上を実装しないのはもったいないでしょう。一方、HTTP/1のエクスペリエンスは非常に陳腐化しているため、プロトコルをまだアップグレードしていないオンプレミス導入でリスクを冒すことは許されません。答えは明確です。どのプロトコルが使用されているかを検出し、最適なポーリング戦略を適用する必要があります。
Kibanaサーバーがどのプロトコルを使用しているかを知ることは確かに可能です。しかし、そこには落とし穴があります:制限要因はブラウザの接続プールです。つまり、本当に重要なのはブラウザが何を使用しているかということです。
プロキシの関係で、これらは必ずしも同じではありません。
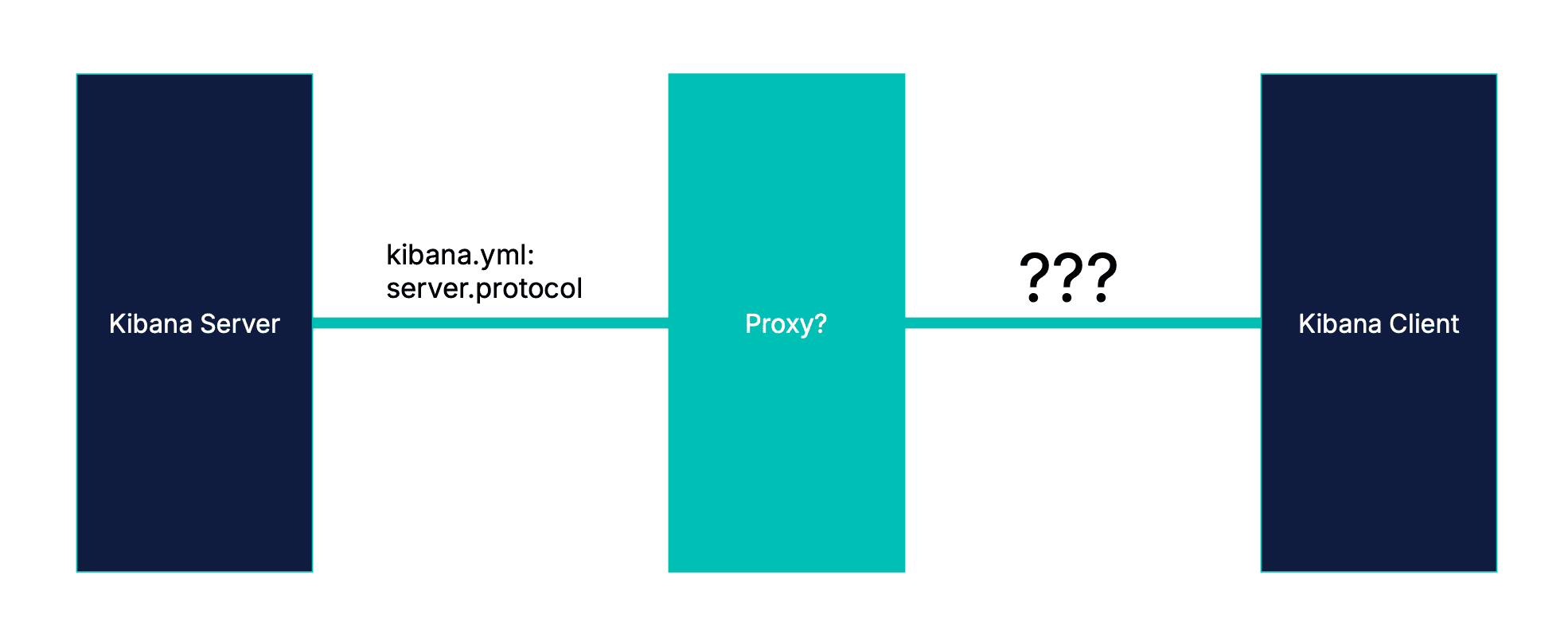
プロトコルはネットワークホップごとに異なる場合があります
最適化をサーバープロトコルに基づいて行うと、2つの誤りのどちらかが起こり得ます。
- 適用すべきでないのに継続的なポーリングを適用し、エクスペリエンスを低下させる。
- 継続的ポーリングを適用すべき場合に適用せず、最適化の機会を逃す。
幸いなことに、最新のブラウザは PerformanceObserver を使用することで、完了したリクエストの最後のネットワークホップのプロトコルを検出する方法を提供しています。そこで、最初のクエリ送信のプロトコルを監視し、それに基づいて最適化します。
ラボでの結果:継続的ポーリングと従来のポーリングとの比較(Kibana)
継続的なポーリングを検証するために、1秒から23秒の範囲でクエリが遅延するダッシュボードを作成し、最適化を有効にした状態と有効にしていない状態での読み込み時間を測定しました。次に、継続的なポーリングが有効なダッシュボードと有効でないダッシュボードを読み込み、その結果を(賞品のかかったレースのように楽しんで)測定しました。
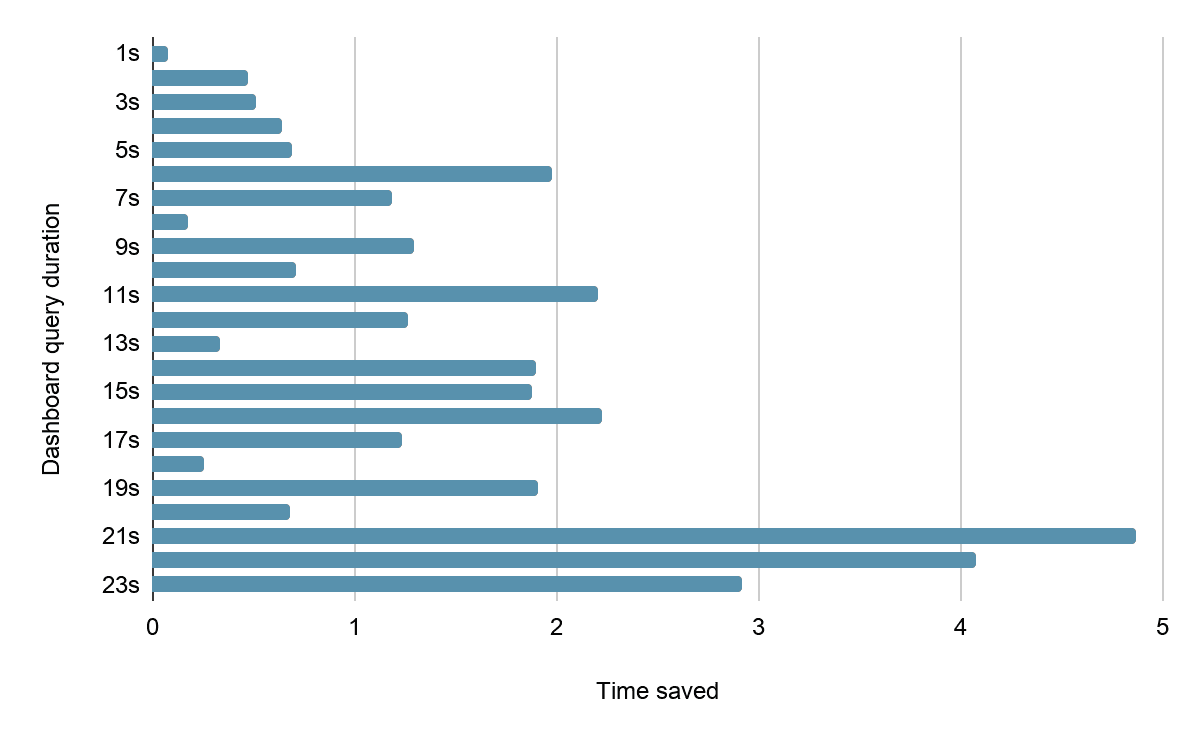
クエリの実行時間別ダッシュボードの読み込み時間
このパターンは、元のノコギリ型の図を踏襲しています。クエリの期間によっては、効果が小さい場合もあれば、数秒に及ぶ場合もあります。
まとめ
この最適化により、従来のポーリング方式に内在する遅延を、より効率的な継続的ポーリング方式に置き換えることに成功しました。主な課題は、HTTP/1環境でのパフォーマンス低下を防ぐために、この最適化を条件付きで実装することでした。私たちはこの課題を、ブラウザの PerformanceObserver を使って、最終ネットワークホップで使用されているプロトコルを確実に検出することで解決しました。
ラボでのテストによりこの理論が検証され、継続的なポーリングによって結果が準備でき次第すぐに得られることが示されました。平均して、これはユーザーエクスペリエンスの有意義な改善につながり、データの読み込みを最大25%高速化します。
この取り組みは、ユーザーが洞察を得るまでの時間を短縮するという私たちのコミットメントにおける、最新のステップです。KibanaをElasticsearchデータに対してより透明性の高いプロキシにすることで、私たちの影響が及ぶ範囲内でのパフォーマンスの限界を押し広げます。ぜひ今後の続報をお待ちください。
(2025年、トーマス・ナイリンクはKibanaのダッシュボードのパフォーマンスを向上させる方法と動機について優れた概要を紹介しました。これはその取り組みをアップデートしたものです。
よくあるご質問
継続的なポーリングは、Kibanaのダッシュボードの読み込みをどのように改善するのでしょうか?
ダッシュボードの読み込み速度は、KibanaがElasticsearchからクエリ結果を取得できる速さによって異なります。従来のポーリングでは、完了を定期的に確認するため、結果の取得に遅延が生じる可能性があります。HTTP/2+では、Kibanaは自動的に継続的なポーリングを有効にし、接続を開いたままにすることで遅延を防ぎ、準備ができ次第すぐに結果を配信します。
継続的ポーリングとは何ですか?また、Kibanaのパフォーマンスはどのように向上しますか?
継続的なポーリングは、定期的なチェックの合間にスリープするのではなく、Elasticsearchのクエリ結果を待つ間、HTTP接続を開いたままにしておくことで、従来のパターンを逆転させます。これにより、時間の無駄がなくなり、準備が整い次第結果が表示されるため、ダッシュボードとDiscoverの表示が高速化されます。
HTTP/1接続で連続ポーリングは機能しますか?
いいえ。継続的なポーリングは、多重化が長時間のリクエストによって他のトラフィックがブロックされるのを防ぐHTTP/2+接続でのみ適用されます。Kibanaはブラウザの PerformanceObserver API を使用してプロトコルを自動的に検出し、HTTP/1 で従来のポーリングを適用してパフォーマンスの低下を回避します。
継続的なポーリングを行うKibanaのダッシュボードはどのくらい速くなりますか?
ラボテストによると、クエリの期間によっては、ダッシュボードの読み込み時間が最大25%改善されることが示されています。長いクエリほど絶対的な節約時間が長く、非常に短いクエリではほとんど差がありません。
Kibanaはどのようにして使用すべきポーリングが継続的ポーリングか従来型ポーリングかを検出するのでしょうか?
Kibanaはブラウザの PerformanceObserver API を使用して、最初のクエリリクエストのHTTPプロトコルを検出します。プロトコルが(多重化をサポートする)HTTP/2またはHTTP/3であれば、継続的ポーリングが有効になります。HTTP/1が検出された場合、接続プールの枯渇を防ぐために従来のポーリングが使用されます。
継続的なポーリングはネットワークプロキシやロードバランサーに問題を引き起こすのでしょうか?
継続的ポーリングは、ブラウザ接続プールの枯渇を避けるためにHTTP/2+多重化に依存しています。プロキシがプロキシとブラウザ間の接続をHTTP/1にダウングレードした場合、Kibanaはこれを検出し、代わりに従来のポーリングを使用します。この最適化は、ブラウザが実際に使用するプロトコルに基づいて条件付きで適用されます。
タイムアウトが発生しています。どうすればいいでしょうか?
プロキシがHTTP/2+を使用している一方、タイムアウトを30秒未満に設定している場合、検索のタイムアウトが発生します。この問題を解決するには、プロキシのタイムアウトまでの時間を伸ばすか、kibana.yml で data.search.asyncSearch.pollLength をタイムアウトより小さい値に設定します。
関連記事
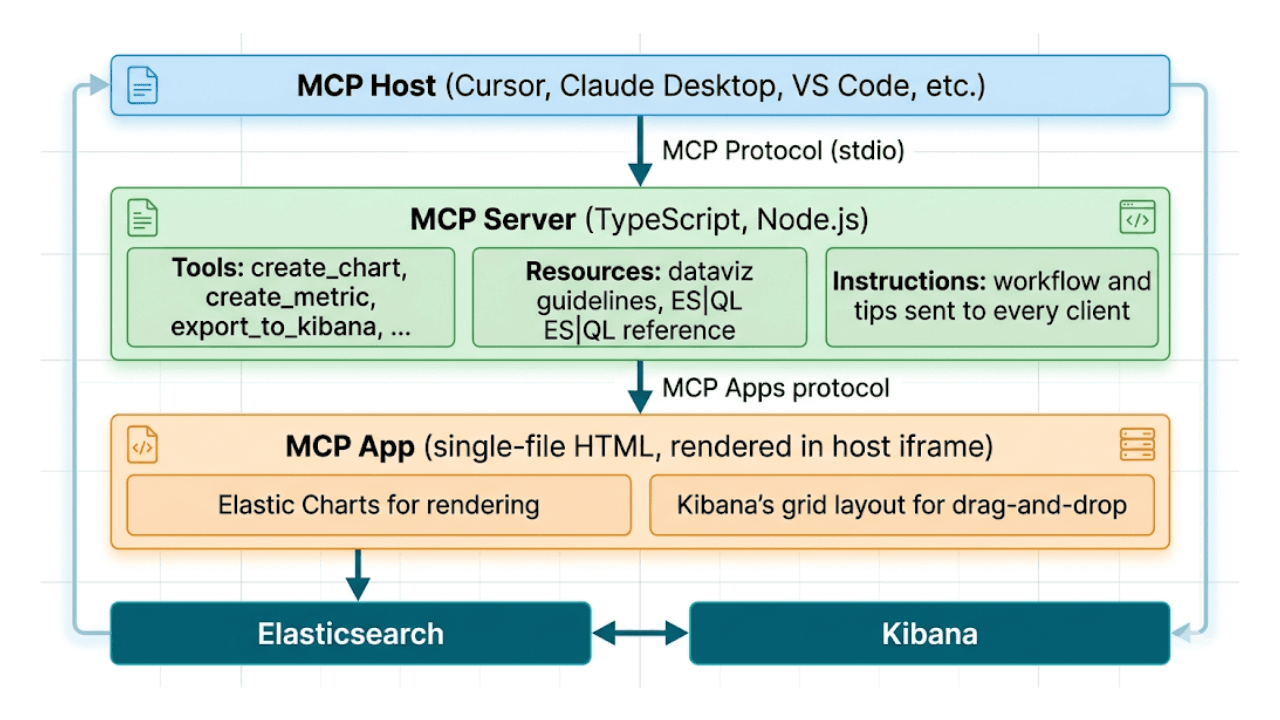
描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

2026年5月25日
KibanaのAI Chatがダッシュボードをネイティブにレンダリングするように
KibanaのElastic AI Chatでは、自然言語からダッシュボードを構築し、ビジュアルと分析を1つのスレッドに保持し、再利用可能なKibanaオブジェクトとして保存できるようになりました。

変数コントロールによるKibanaダッシュボードのインタラクション性の向上
Kibana 8.18+の変数コントロールを使用して、個々の可視化をフィルタリングし、時間間隔を調整し、Kibanaダッシュボード内の異なるフィールドでグループ化する方法を学びます。