Les tableaux de bord Kibana et Discover se chargent désormais jusqu'à 25 % plus rapidement grâce à l'interrogation continue. Au lieu d'interrompre l'exécution entre les vérifications périodiques, Kibana maintient les connexions HTTP ouvertes et fournit les résultats des requêtes Elasticsearch dès qu'ils sont disponibles. Sur HTTP/2 et versions ultérieures (configuration par défaut de Kibana depuis la version 9.0), cette fonctionnalité est activée automatiquement, sans aucune configuration nécessaire. Sur HTTP/1, Kibana utilise l'interrogation classique pour éviter la saturation du pool de connexions.
Comment Kibana récupère les données lors du chargement d'un tableau de bord
Lorsqu'un tableau de bord est ouvert, la plupart des panneaux, (en interne, nous les appelons panneaux intégrables) lancent une ou plusieurs requêtes Elasticsearch. Mais au lieu du simple échange d'appels et de réponses d'une recherche synchrone (sync), nous utilisons la puissance de la recherche asynchrone (async) (documentation).
Avec la recherche asynchrone, les résultats des requêtes restent disponibles dans Elasticsearch en dehors de toute requête HTTP particulière. Ce point est important, car il
- rend le chargement des données résistant aux perturbations du réseau.
- alimente notre fonctionnalité de recherche en arrière-plan, qui permet aux utilisateurs de travailler sur d'autres éléments dans Kibana pendant qu'ils attendent la fin d'une session de tableau de bord ou Discover de longue durée.
Une fois la requête initiale envoyée, Kibana surveille la recherche pour détecter sa fin et récupérer l'ensemble des résultats.
Comment l'interrogation classique affecte les temps de chargement du tableau de bord Kibana
Dans le système d'interrogation traditionnel, Kibana envoie une requête, ferme la connexion initiale, puis vérifie périodiquement auprès d'Elasticsearch si l'opération est terminée.
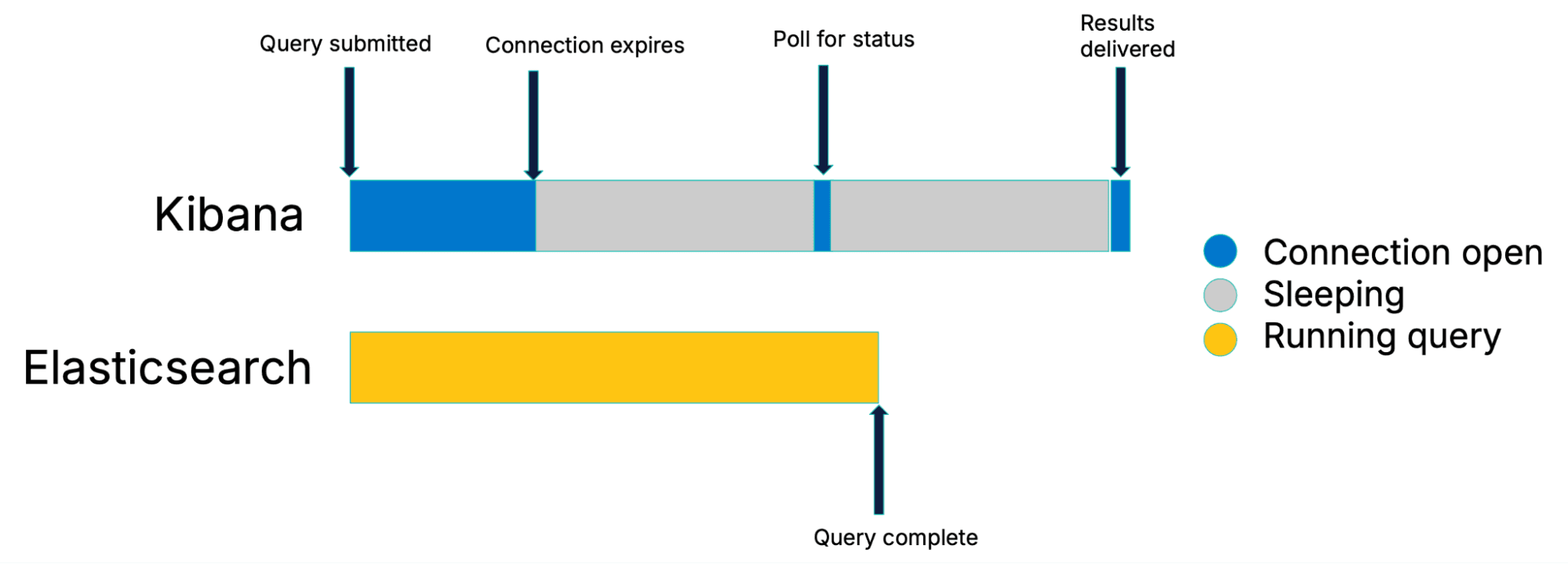
Stratégie de sondage traditionnelle
Après l'envoi d'une requête, Elasticsearch dispose d'un court laps de temps pour effectuer la recherche et renvoyer les résultats. Si la recherche s'achève rapidement, il s'agit d'un simple échange de données. En revanche, pour les recherches plus longues, la connexion initiale est fermée et Kibana vérifie régulièrement l'état d'avancement de la recherche. Ce processus est appelé interrogation.
Inconvénients de l'interrogation classique en termes de performance
Si vous observez la figure ci-dessus, vous pouvez constatez peut-être l'inconvénient de cette approche en termes de performances : la recherche a de fortes chances de se terminer pendant l'un des intervalles d'inactivité de Kibana, ce qui entraîne une perte de temps.
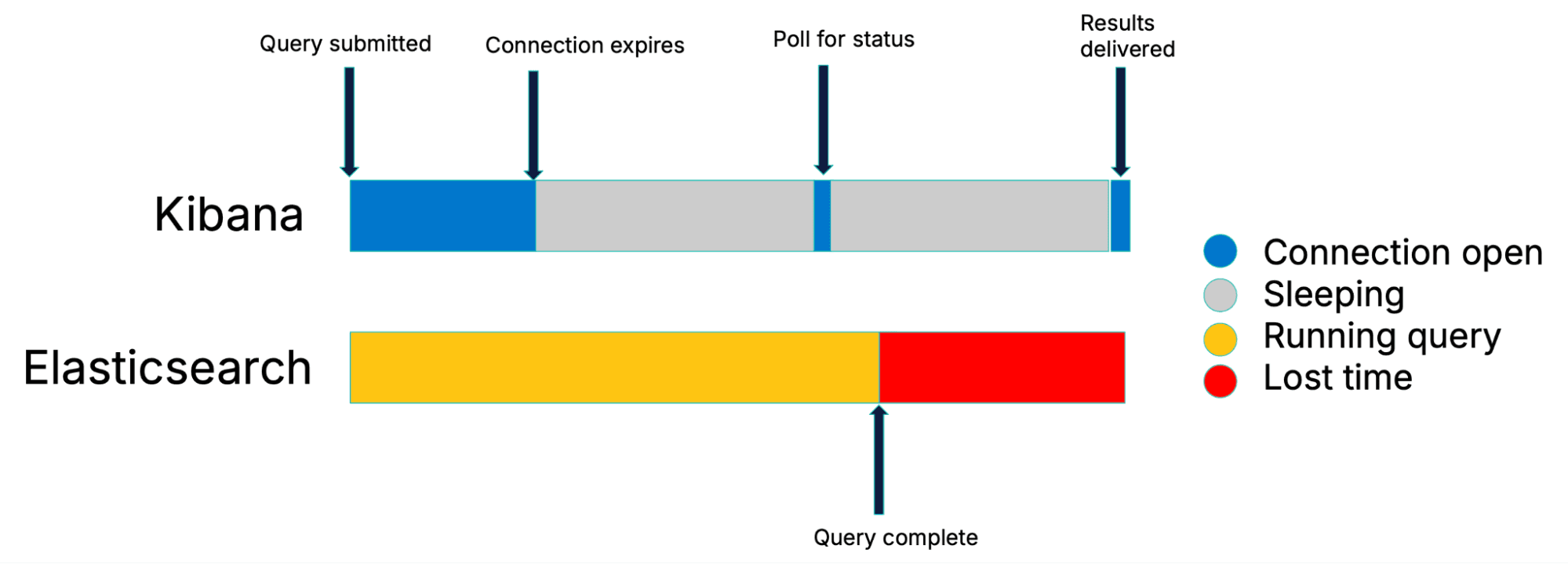
Le côté obscur des sondages traditionnels
Dans le pire des cas (lorsqu'une recherche se termine au début d'une période d'inactivité), toute la durée de l'intervalle d'interrogation sera perdue.
L'impact d'une stratégie de temporisation
Il est d'usage, lors des interrogations, d'appliquer une stratégie de temporisation. Cela signifie que plus la durée de la recherche est longue, moins les interrogations sont fréquentes.
Programme de temporisation des intervalles d'interrogation
Toutefois, cela signifie également que le temps potentiellement perdu est proportionnel à la durée de la recherche.
Comment les intervalles d'interrogation créent des schémas de latence en dents de scie
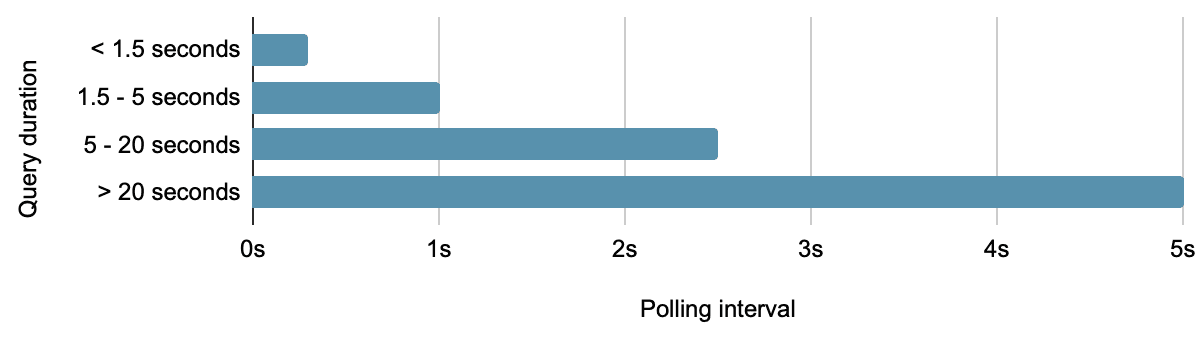
En rassemblant ces facteurs, notre temps perdu devient une fonction en dents de scie par paliers.

Temps perdu en fonction de la durée de la requête
Ici, les pics représentent les scénarios les plus défavorables et les creux les scénarios les plus favorables. Cela montre que le coût d'un système d'interrogation traditionnel varie de zéro à la durée totale de l'intervalle d'interrogation, selon la durée de la recherche (et les conditions du réseau).
Interrogation continue : comment Kibana élimine les temps d'attente
Le problème avec les interrogations classiques est le manque fondamental de coordination entre Kibana et Elasticsearch. Idéalement, Kibana devrait être informé immédiatement de la disponibilité des résultats. Et si l'on inversait le schéma d'interrogation pour que la quasi-totalité du temps soit consacrée à la vérification d'Elasticsearch, sans aucune interruption ?
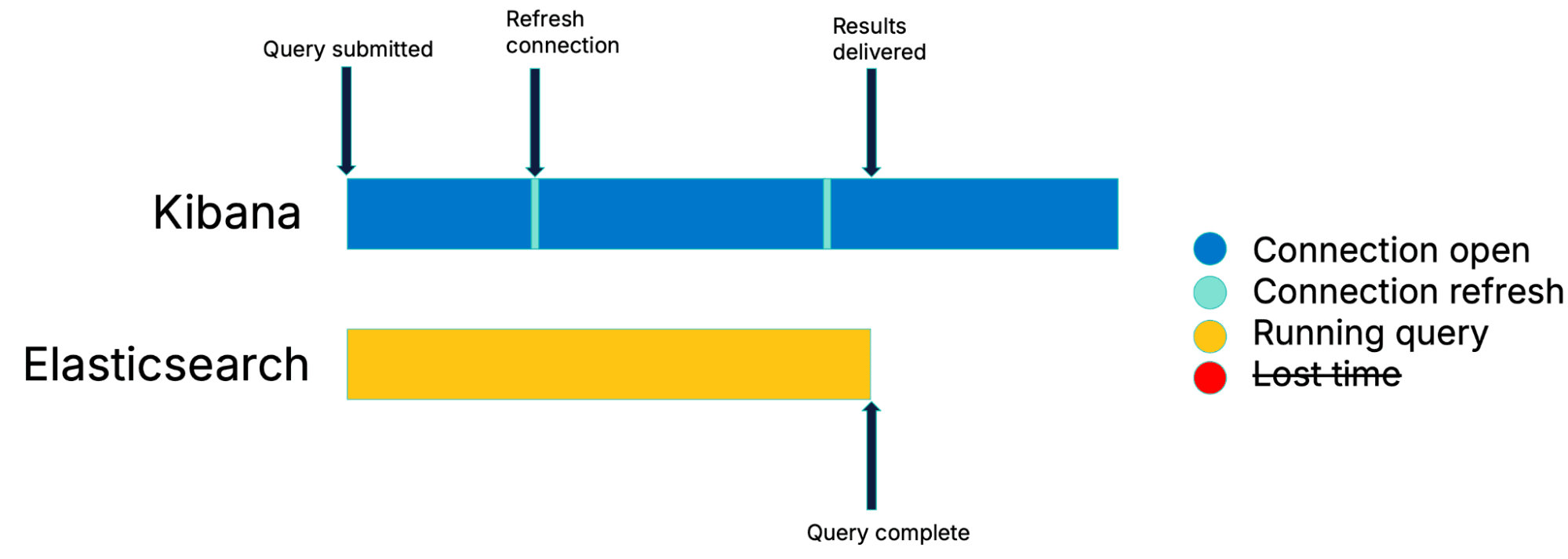
Interrogation continue : une solution au temps perdu
Avec cette combinaison d'interrogations de longue durée et d'absence de périodes de veille, les résultats sont transmis dès qu'ils sont prêts.
Dégradation HTTP/1
La théorie tient la route. Alors pourquoi ce déploiement Kibana semble-t-il si dégradé lorsque nous activons l'interrogation continue ?
L'interrogation continue provoque une dégradation des performances sur les clients connectés via HTTP/1
Le point important est que ce déploiement s'exécute sur HTTP/1. Avec HTTP/1, les requêtes HTTP sont associées une à une à des connexions TCP. Par conséquent, plusieurs requêtes d'interrogation de longue durée monopolisent le nombre limité de connexions du navigateur, ce qui entraîne la mise en file d'attente d'autres requêtes.
En revanche, avec HTTP/2+, les requêtes réseau peuvent partager des connexions TCP via le multiplexage, ce qui nous évite ce problème.
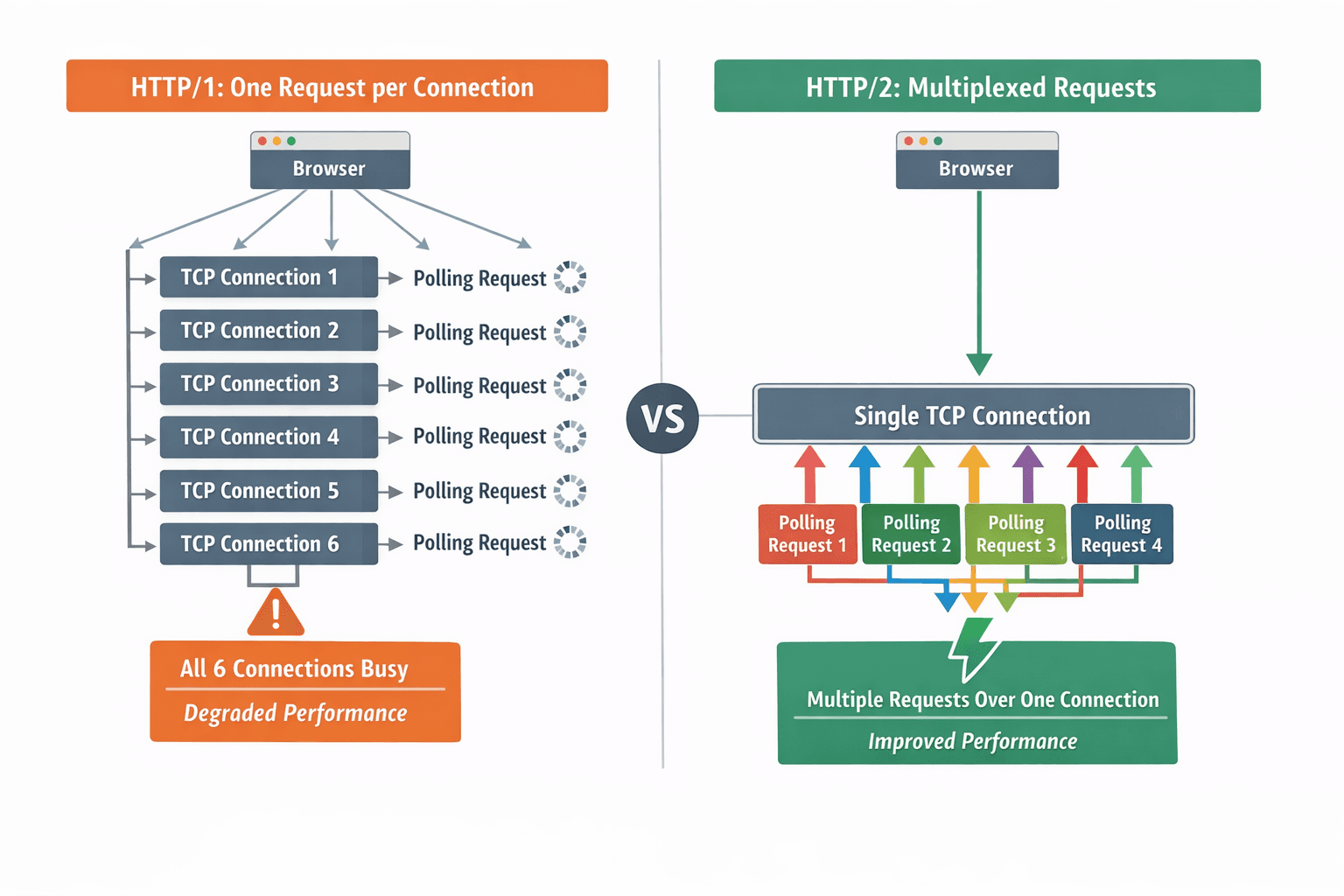
Différence dans le mapping HTTP-TCP entre HTTP/1 et HTTP/2+
Ainsi, sur HTTP/2+, l'interrogation continue est une vertu, mais sur HTTP/1, elle devient un vice.
| HTTP/1 | HTTP/2+ | |
|---|---|---|
| Connexions TCP | Une par requête HTTP | Multiplexée (plusieurs requêtes partagent les mêmes connexions) |
| Comportement de l'interrogation continue | Dégrade les performances (saturation du pool de connexions) | Bénéfice complet (résultats immédiats) |
Comment Kibana détecte le protocole HTTP pour une interrogation optimale
HTTP/2 est le protocole recommandé et celui par défaut de Kibana depuis la version 9.0 ; il serait donc dommage de ne pas intégrer cette amélioration des performances. En revanche, l'expérience utilisateur avec HTTP/1 est tellement dégradée qu'il est inacceptable de prendre le risque de l'utiliser sur les déploiements sur site dont le protocole n'a pas encore été mis à niveau. La solution est claire : nous devons détecter le protocole utilisé et appliquer la stratégie d'interrogation optimale.
Il est tout à fait possible que le serveur Kibana sache quel protocole il utilise. Cependant, il y a un hic : le facteur limitant est le pool de connexions du navigateur. Autrement dit, ce qui compte vraiment, c'est le protocole utilisé par le navigateur.
En raison des proxys, ceux-ci ne sont pas toujours identiques.
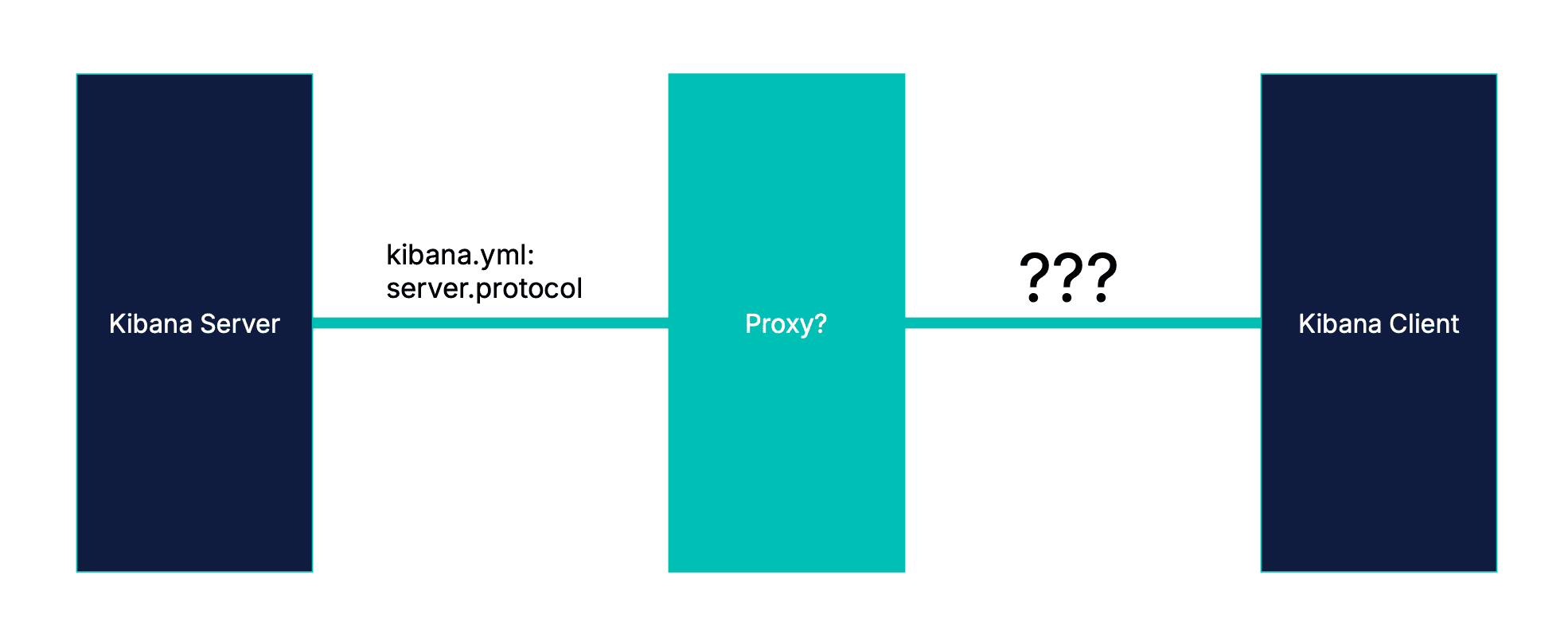
Le protocole peut différer pour chaque saut de réseau
Si nous basons notre optimisation sur le protocole du serveur, nous pourrions nous tromper de deux manières.
- Appliquer une interrogation continue à tort et dégrader l'expérience utilisateur.
- Ne pas parvenir à appliquer une interrogation continue quand il le faudrait et passer à côté de l'optimisation.
Heureusement, les navigateurs modernes permettent de détecter le protocole du dernier saut réseau de toute requête terminée grâce à l'utilisation de PerformanceObserver. Ainsi, nous surveillons le protocole du premier envoi de requête et optimisons en conséquence.
Résultats en laboratoire : interrogation continue et interrogation classique dans Kibana
Pour valider l'interrogation continue, nous avons créé des tableaux de bord avec des délais de requête allant de 1 à 23 secondes et mesuré les temps de chargement avec et sans l'optimisation activée. Nous avons ensuite chargé les tableaux de bord avec et sans interrogation continue pour mesurer les gains (nous nous sommes bien amusés avec la course aux prix).
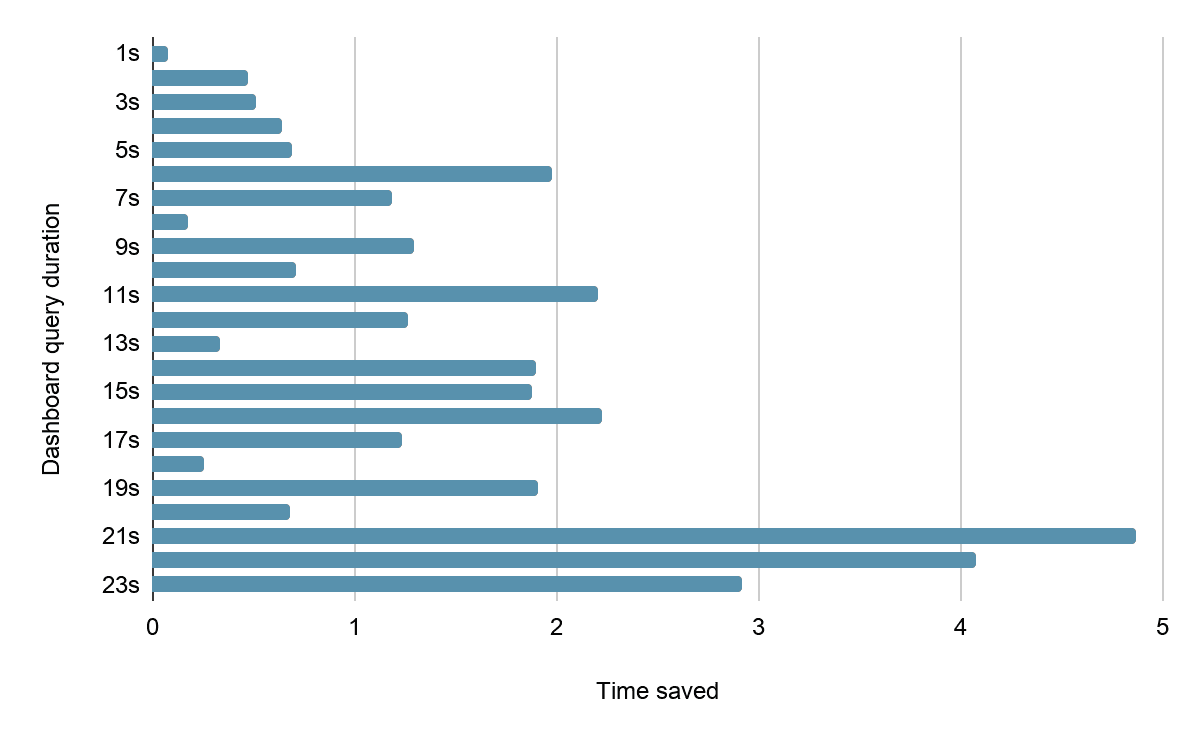
Temps de chargement du tableau de bord par durée de requête
Ce schéma rappelle notre diagramme en dents de scie initial. Pour certaines durées de requête, les gains sont faibles, tandis que pour d'autres, ils atteignent plusieurs secondes.
Conclusion
Cette optimisation remplace efficacement la latence inhérente à l'interrogation classique par une stratégie d'interrogation continue plus performante. La principale difficulté résidait dans la mise en œuvre conditionnelle de cette optimisation afin d'éviter toute dégradation des performances sur les déploiements HTTP/1. Nous l'avons résolue en utilisant la fonction PerformanceObserver du navigateur pour détecter de manière fiable le protocole utilisé pour le dernier saut du réseau.
Des tests en laboratoire valident cette théorie, démontrant que l'interrogation continue fournit des résultats dès qu'ils sont disponibles. En moyenne, cela se traduit par une amélioration significative de l'expérience utilisateur, avec un temps de chargement des données jusqu'à 25 % plus rapide.
Ce travail représente la dernière étape de notre engagement à réduire le délai d'accès aux informations pour nos utilisateurs. En faisant de Kibana un proxy plus transparent pour les données Elasticsearch, nous optimisons les performances dans notre domaine d'expertise. À suivre !
(En 2025, Thomas Neirynk a donné un excellent aperçu des méthodes et des motivations derrière l'amélioration des performances du tableau de bord Kibana. Ceci est une mise à jour de cette initiative.)
Questions fréquentes
Comment l'interrogation continue améliore-t-elle le chargement des tableaux de bord dans Kibana ?
La vitesse de chargement du tableau de bord dépend de la rapidité avec laquelle Kibana récupère les résultats des requêtes Elasticsearch. L'interrogation classique vérifie périodiquement la fin des requêtes, ce qui peut entraîner des délais. Avec HTTP/2+, Kibana active automatiquement une interrogation continue, éliminant ainsi les délais en maintenant les connexions ouvertes et en fournissant les résultats immédiatement dès qu'ils sont disponibles.
Qu'est-ce que l'interrogation continue et comment cela améliore-t-il les performances de Kibana ?
L'interrogation continue inverse le schéma traditionnel en maintenant les connexions HTTP ouvertes pendant l'attente des résultats des requêtes Elasticsearch, au lieu d'interrompre le processus entre les vérifications périodiques. Cela élimine les pertes de temps et fournit les résultats dès qu'ils sont disponibles, accélérant ainsi l'affichage des tableaux de bord et de Discover.
Le sondage continu fonctionne-t-il sur les connexions HTTP/1 ?
Non. L'interrogation continue est uniquement appliquée aux connexions HTTP/2+, où le multiplexage empêche les requêtes de longue durée de bloquer le reste du trafic. Kibana détecte automatiquement le protocole grâce à l'API PerformanceObserver du navigateur et applique une interrogation classique sur HTTP/1 afin d'éviter toute dégradation des performances.
Dans quelle mesure les tableaux de bord Kibana sont-ils plus rapides grâce à l'interrogation continue ?
Les tests en laboratoire montrent que les temps de chargement des tableaux de bord s'améliorent jusqu'à 25 % selon la durée de la requête. Les requêtes plus longues bénéficient de gains de temps absolus plus importants, tandis que les requêtes très courtes ne présentent qu'une différence minime.
Comment Kibana détecte-t-il s'il doit utiliser un système d'interrogation continue ou classique ?
Kibana utilise l'API PerformanceObserver du navigateur pour détecter le protocole HTTP de la première requête. Si le protocole est HTTP/2 ou HTTP/3 (qui prennent en charge le multiplexage), l'interrogation continue est activée. Si HTTP/1 est détecté, une interrogation classique est utilisée afin d'éviter la saturation du pool de connexions.
L'interrogation continue risque-t-elle de poser des problèmes avec mon proxy réseau ou mon équilibreur de charge ?
L'interrogation continue repose sur le multiplexage HTTP/2+ pour éviter la saturation du pool de connexions du navigateur. Si votre proxy rétrograde les connexions en HTTP/1 entre le proxy et le navigateur, Kibana le détectera et utilisera alors une interrogation classique. L'optimisation est appliquée conditionnellement en fonction des données échangées par le navigateur.
Je constate des délais d'attente. Que dois-je faire ?
Si votre proxy utilise HTTP/2+ mais impose un délai d’attente inférieur à 30 secondes, vous constaterez des délais d’attente lors des recherches. Pour résoudre ce problème, augmentez le délai d’attente de votre proxy ou définissez la propriété data.search.asyncSearch.pollLength dans votre fichier kibana.yml sur une valeur inférieure à votre délai d’attente.
Pour aller plus loin
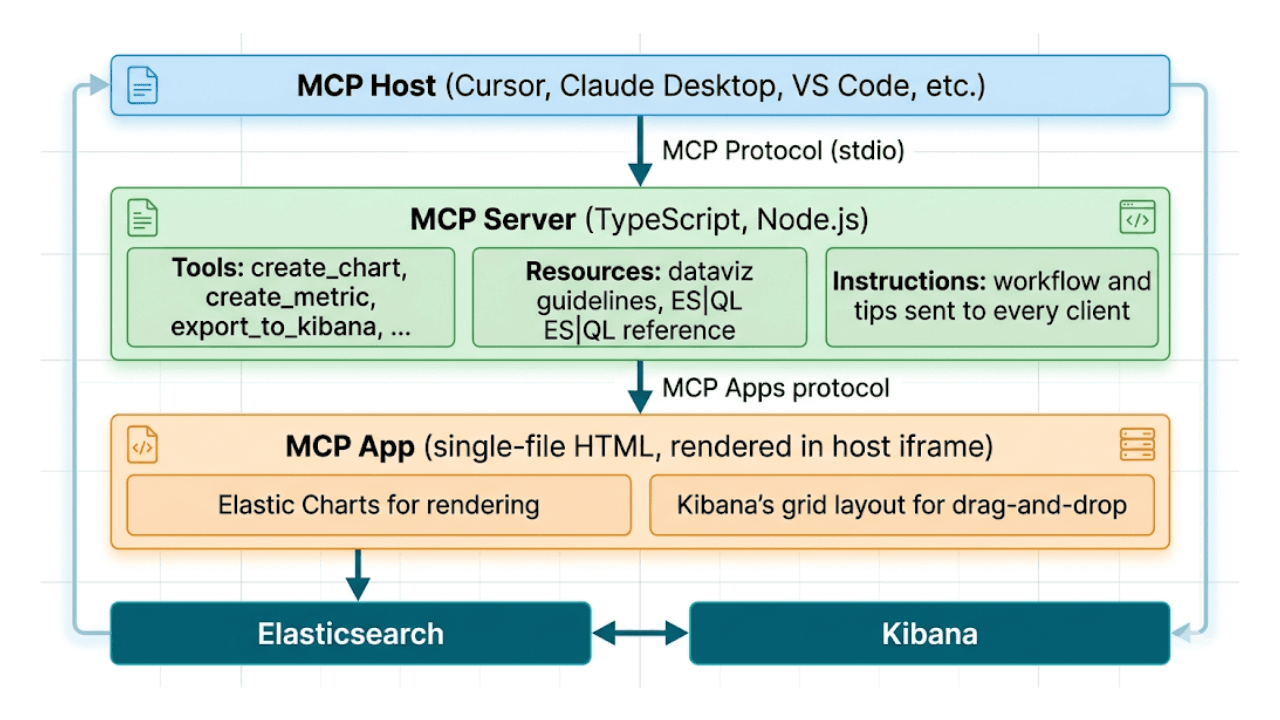
Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

25 mai 2026
AI Chat dans Kibana prend désormais en charge l'affichage natif des tableaux de bord
Elastic AI Chat dans Kibana permet désormais de créer des tableaux de bord à partir du langage naturel. Vos visualisations et analyses sont conservées dans un seul fil de discussion et vous pouvez les enregistrer en tant qu'objets Kibana réutilisables.

4 décembre 2025
Améliorer l'interactivité des tableaux de bord Kibana grâce aux contrôles variables
Découvrez comment utiliser les contrôles variables dans Kibana 8.18+ pour filtrer les visualisations individuelles, ajuster les intervalles de temps et regrouper les données par champs dans les tableaux de bord Kibana.
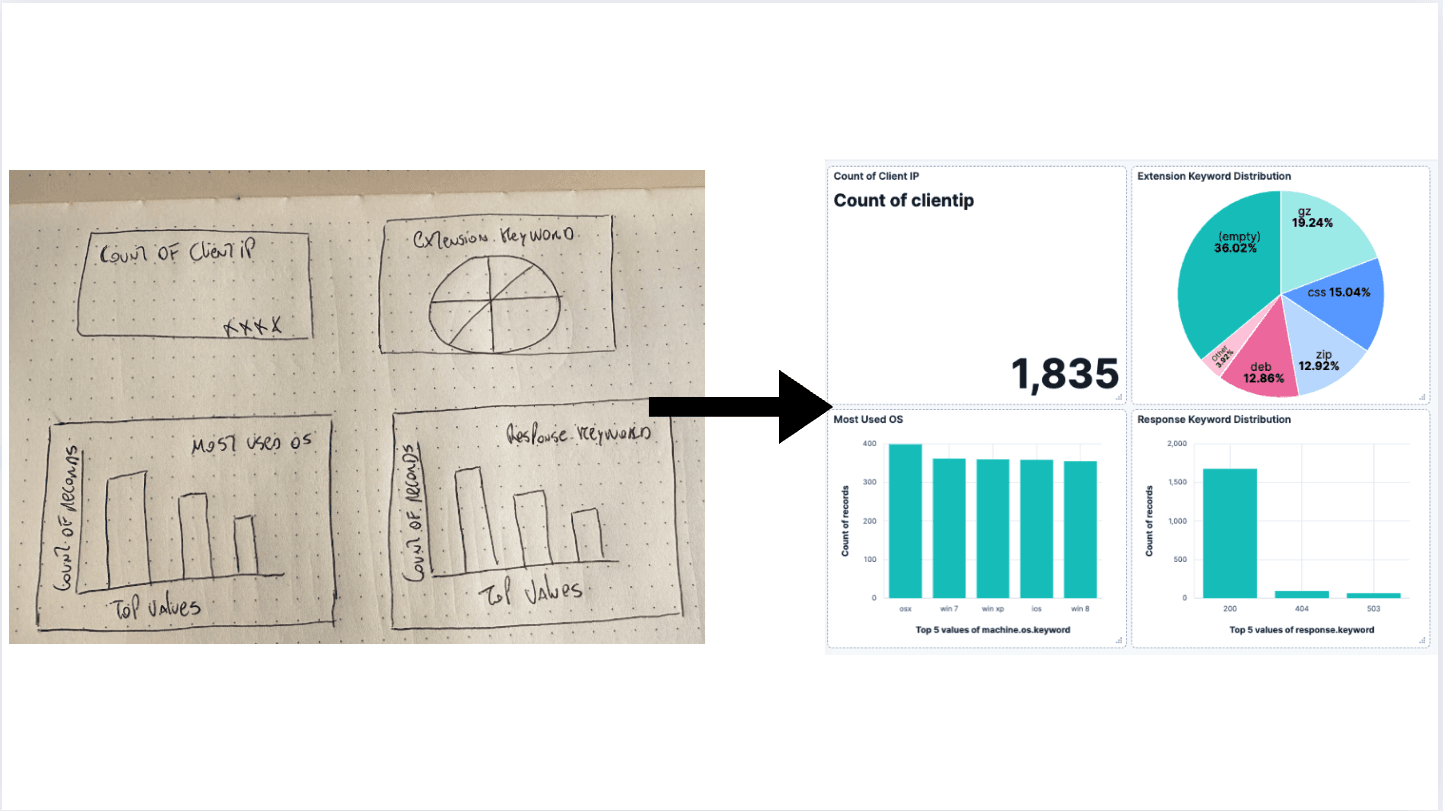
Tableaux de bord alimentés par l'IA : D'une vision à Kibana
Générer un tableau de bord en utilisant un LLM pour traiter une image et la transformer en tableau de bord Kibana.

25 février 2025
Spotify Wrapped partie 2 : Analyse et visualisation des données
Nous allons plonger plus profondément que jamais dans vos données Spotify et explorer des connexions dont vous ne soupçonniez même pas l'existence.