Heute stellen wir jina-embeddings-v3 vor, das erste Search Foundation Model von Jina vor, das im Model Garden der Gemini Enterprise Agent Platform als Self-Deployment-Modell verfügbar ist. Self-Deployment bedeutet, dass das Modell auf GPU-Instanzen innerhalb Ihres Google Cloud-Projekts und Ihrer Virtual Private Cloud (VPC) ausgeführt wird. Keine externen API-Aufrufe, keine Abrechnung pro Token, keine Ratenbegrenzungen.
Mit dieser Integration erhalten Elasticsearch-Nutzer eine neue Deployment-Option, bei der die Daten innerhalb ihres Sicherheitsperimeters verbleiben, die Infrastrukturkosten vorhersehbar sind und die nativ auf Google Cloud ausgeführt wird. Gleichzeitig erhält das gesamte Google Cloud-Ökosystem Zugriff auf die speziell entwickelten, fortschrittlichen Such- und Abrufmodelle von Jina.
Es handelt sich hierbei um die erste Phase einer umfassenderen Einführung. Zusammen mit den kommenden Modellen wird das Angebot einen vollständigen Retrieval-Stack bilden: Betten Sie Ihre Daten und Abfragen ein, rufen Sie Kandidaten ab und ordnen Sie sie neu, und erweitern Sie die Suche mithilfe multimodaler Einbettungen auf Bilder – alles auf einer von Ihnen kontrollierten Infrastruktur. Sie können noch heute mit jina-embeddings-v3 loslegen – dem Modell, das über den Elastic Inference Service (EIS) bereits Produktions-Suchpipelines im gesamten Elasticsearch-Ökosystem unterstützt.
| Modell | Typ | Parameter | Wichtige Funktion | Status im Model Garden |
|---|---|---|---|---|
| „jina-embeddings-v3“ | Texteinbettungen | 572 Mio. | Bewährtes mehrsprachiges Tool, Kontextlänge von 8.000, Ausgabedimension von 1.024, auf 32 kürzbar | Jetzt verfügbar |
| „jina-embeddings-v5-text-small“ | Texteinbettungen | 677 Mio. | Fortschrittliches mehrsprachiges Tool mit weniger als 1 Mrd. Parametern, Kontextlänge von 32.000, Ausgabedimension von 1.024, auf 32 kürzbar | Demnächst verfügbar |
| „jina-embeddings-v5-text-nano“ | Texteinbettungen | 239 Mio. | Branchenführend unter 500 Mio. Parametern, Kontextlänge von 8.000, Ausgabedimension von 768, auf 32 kürzbar | Demnächst verfügbar |
| „jina-reranker-v3“ | Reranker | 600M | Listwise-Reranker, Kontextlänge von 131.000, bis zu 64 Dokumente | Demnächst verfügbar |
| „jina-clip-v2“ | Multimodale Einbettung | 900M | Text und Bild im gemeinsamen Bereich, 89 Sprachen und Textkontextlänge von 8.000, Bilder mit einer Größe von 512 × 512 | Demnächst verfügbar |
Jedes Modell wird auf einem einzelnen NVIDIA L4 (24 GB) ausgeführt, der kostengünstigsten GPU-Stufe in Google Cloud. Die meisten anderen Einbettungsmodelle im Google Cloud Model Garden erfordern einen A100 80 GB oder einen H100, was etwa dem Dreifachen der Instanzkosten pro Stunde entspricht, noch bevor Token berücksichtigt werden.
Beim Deployment über Vertex AI ist keine zusätzliche kommerzielle Lizenz erforderlich.
Warum Model Garden?
Warum das Deployment über Model Garden statt über eine API? Letztendlich kommt es auf drei Faktoren an: Kontrolle, Kosten und Kontext.
Ihre Daten verlassen niemals das Gebäude
Der größte Anreiz für die meisten Entwickler ist die Self-Deployment-Architektur. Beim Deployment eines Jina-Modells über Model Garden werden die Gewichte auf GPU-Instanzen innerhalb Ihres eigenen Google Cloud-Projekts und Ihrer eigenen VPC ausgeführt. Dieser entscheidende Vorteil kommt allen zugute, die in Branchen mit hohen Anforderungen an die Datensicherheit tätig sind, wie beispielsweise im Finanzwesen oder im Gesundheitswesen. Da keine externen API-Aufrufe erfolgen, verbleiben Ihre sensiblen Daten innerhalb Ihres Sicherheitsperimeters.
Skalierung mit Prognose
Anstatt jedes Mal zu zahlen, wenn Sie einen Satz einbetten oder ein Dokument neu anordnen, zahlen Sie eine pauschale stündliche Instanzgebühr. Und da jedes Jina-Modell auf einer einzigen NVIDIA L4, der günstigsten GPU-Stufe in der Google Cloud, ausgeführt werden kann, ist die Einstiegshürde niedrig. Ganz gleich, ob Sie tausend oder eine Milliarde Anfragen bearbeiten – Ihre Infrastrukturkosten bleiben kalkulierbar. Bei diesem Modell werden Sie für die Steigerung Ihres Traffics belohnt, anstatt dafür zur Kasse gebeten zu werden.
Alles unter einem Dach
Wenn Ihre Daten bereits in Elasticsearch auf Google Cloud, in BigQuery oder in Cloud Storage gespeichert sind, ist es sinnvoll, Ihre Inferenz-Engines in der Nähe zu belassen. Durch das Deployment über Model Garden profitieren die Search Foundation Models von Jina von allen Unternehmensfunktionen, die Sie bereits nutzen: Identitäts- und Zugriffsverwaltung (IAM) für die Zugriffskontrolle, eine einheitliche Abrechnung über Ihre bestehende Google Cloud-Rechnung sowie die Möglichkeit zur Integration in Vertex AI Pipelines für MLOps-Workflows (Machine Learning Operations).
Während die Jina AI Cloud API und Elastic Cloud den schnellsten Weg für Spitzenauslastungen oder bestehende Such-Workflows bieten, eignet sich Model Garden insbesondere für Unternehmensanwendungen, die strenge Datensicherheit und vorhersehbare Kosten im großen Maßstab erfordern. Elastic möchte Sie dort abholen, wo Sie gerade stehen.
Jina AI-Modelle
jina-embeddings-v3
Unser bewährtes mehrsprachiges Einbettungsmodell mit 572 Mio. Parametern und einem Kontext von 8.000 Tokens. Erzielt 65,5 Punkte beim Massive Text Embedding Benchmark (MTEB) für Englisch. Unterstützt fünf aufgabenspezifische LoRA-Adapter (Abfrage/Passage, Textvergleich, Klassifizierung, Clustering) und Matrjoschka-Kürzungen von 1.024 auf 64 Dimensionen. Wird im gesamten Elasticsearch-Ökosystem über EIS bereits umfassend eingesetzt.
Wir setzen auf v3, da viele Produktionssysteme bereits davon abhängig sind. Wenn Sie eine v3-basierte Pipeline zu Google Cloud migrieren, können Sie dasselbe Modell jetzt nativ ausführen, ohne Ihre Einbettungsdimensionen zu ändern oder neu zu indizieren.
jina-embeddings-v5-text (Small und Nano)
Unsere im Februar 2026 veröffentlichten Texteinbettungsmodelle der fünften Generation erzielen Spitzenleistungen und können mit Modellen mithalten, die um ein Vielfaches größer sind.
v5-text-small (677 Mio.) erzielt 67,0 Punkte in der Multilingual MTEB (MMTEB) Benchmark-Suite, die 131 Aufgaben aus neun Aufgabentypen umfasst, und 71,7 Punkte im MTEB-Benchmark für Englisch. Es handelt sich um das leistungsstärkste mehrsprachige Einbettungsmodell mit weniger als 1 Mrd. Parametern auf dem MTEB-Leaderboard.
v5-text-nano (239 Mio.) erzielt 65,5 Punkte im MMTEB. Kein anderes Modell mit weniger als 500 Mio. Parametern erreicht diesen Wert. Da es weniger als halb so groß ist wie die meisten vergleichbaren Modelle, ist es die naheliegende Wahl für Edge-Anwendungen und latenzkritische Deployments.
Beide Modelle unterstützen:
- Vier aufgabenspezifische LoRA-Adapter: Abruf, Textabgleich, Klassifikation, Clustering. Auswahl eines geeigneten Adapters über den Parameter
taskzum Zeitpunkt der Inferenz. - Kürzungen von Matrjoschka-Dimensionen: Reduziert die Einbettungsdimensionen von 1.024 (bzw. 768 bei Nano) auf 32. Bei moderater Kürzung (zum Beispiel 256 Dimensionen) ist der Qualitätsverlust minimal. Eine Halbierung der Dimensionen reduziert den Speicherbedarf in etwa um die Hälfte.
- Binäre Quantisierung: Komprimiert Einbettungen mit 1.024 Dimensionen durch Binarisierung von 2 KB auf 128 Byte. Durch spezielles Training sind die Verluste bei dieser Komprimierung minimal.
- Mehrsprachig: 119 Sprachen (Small) und 93 (Nano).
jina-reranker-v3
Ein mehrsprachiger Listwise-Reranker mit 0,6 Mrd. Parametern, der auf einer „Last but not late“-Interaktionsarchitektur basiert. Die Abfrage und bis zu 64 mögliche Kandidaten werden in ein einziges Kontextfenster mit 131.000 Token eingegeben, und das Modell führt vor der Bewertung einen dokumentenübergreifenden Vergleich durch. Jina Reranker v3 erreicht auf BEIR einen nDCG@10-Wert von 61,94 und übertrifft damit bei einer sechsmal geringeren Größe das Modell. Damit unterscheidet es sich grundlegend von punktuellen Rerankern, die jedes Dokument isoliert bewerten, und liefert insbesondere beim Abrufen von Passagen aus einzelnen Dokumenten bessere Ergebnisse.
jina-clip-v2
Ein multimodales, mehrsprachiges Einbettungsmodell mit 0,9 Mrd. Parametern, das Text und Bilder in einen gemeinsamen Bereich mit 1.024 Dimensionen abbildet. Es unterstützt:
- 89 Sprachen für den Abruf von Texten und Bildern.
- 512 × 512 Bildauflösung.
- Texteingabe für 8.000 Token.
- Matroschka-Kürzung von 1.024 auf 64 Dimensionen für beide Modalitäten.
Sehr wettbewerbsfähig bei Bild-zu-Text-Benchmarks, einschließlich mehrsprachiger Aufgaben.
Erste Schritte
Jina Embeddings v3 ist ab heute auf Model Garden verfügbar. Hier erfahren Sie, wie es funktioniert.
Sie benötigen ein Google Cloud-Projekt, in dem die Vertex AI-API aktiviert ist und das über genügend GPU-Kontingent für mindestens eine g2-standard-8-Instanz (NVIDIA L4) verfügt. Wenn Sie noch keine Erfahrung mit Google Cloud haben, beginnen Sie mit dem Einrichtungsleitfaden.
Die Model Garden-Seite für Jina Embeddings v3 führt Sie durch den gesamten Ablauf: Laden Sie das Modell hoch, erstellen Sie einen Endpoint, wählen Sie Ihren Maschinentyp aus und führen Sie das Deployment durch. Öffnen Sie es in Ihrem eigenen Projekt und folgen Sie den Anweisungen. A100- und H100-Maschinen sind ebenfalls verfügbar, sofern Region und Kontingent dies zulassen, aber für den Anfang reicht L4 völlig aus.
Vom Klicken bis zur ersten Einbettung dauert der gesamte Vorgang nur wenige Minuten.
Was als Nächstes kommt
Jina Embeddings v3 ist der Ausgangspunkt. In den kommenden Wochen werden wir den Rest des Jina-Retrieval-Stacks in Model Garden integrieren: v5-Text-Embeddings (Small und Nano), jina-reranker-v3 sowie jina-clip-v2 für die multimodale Suche. Alle Modelle laufen auf einer einzigen L4-GPU mit demselben Self-Deployment-Modell.
Zugehörige Inhalte

11. Mai 2026
Ein Index, alle Medien: Einführung von Jina-Embeddings-v5-Omni
Mit jina-embeddings-v5-omni können Sie Text, Bilder, Videos und Audiodateien in einen einzigen Elasticsearch-Index einbetten und gleichzeitig abfragen.

23. Februar 2026
jina-embeddings-v5-text: Kompakte, hochmoderne Texteinbettungen für Suchen und intelligente Anwendungen
Einführung der jina-embeddings-v5-text-Modelle, darunter jina-embeddings-v5-text-small und jina-embeddings-v5-text-nano, sowie eine Erklärung zur Nutzung dieser mehrsprachigen Einbettungsmodelle über den Elastic Inference Service (EIS).
1. Januar 2026
Eine Einführung in Jina-Modelle, ihre Funktionalität und ihre Einsatzmöglichkeiten in Elasticsearch
Entdecken Sie multimodale Einbettungen von Jina, Reranker v3 und semantische Einbettungsmodelle und erfahren Sie, wie Sie diese nativ in Elasticsearch verwenden können.

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.
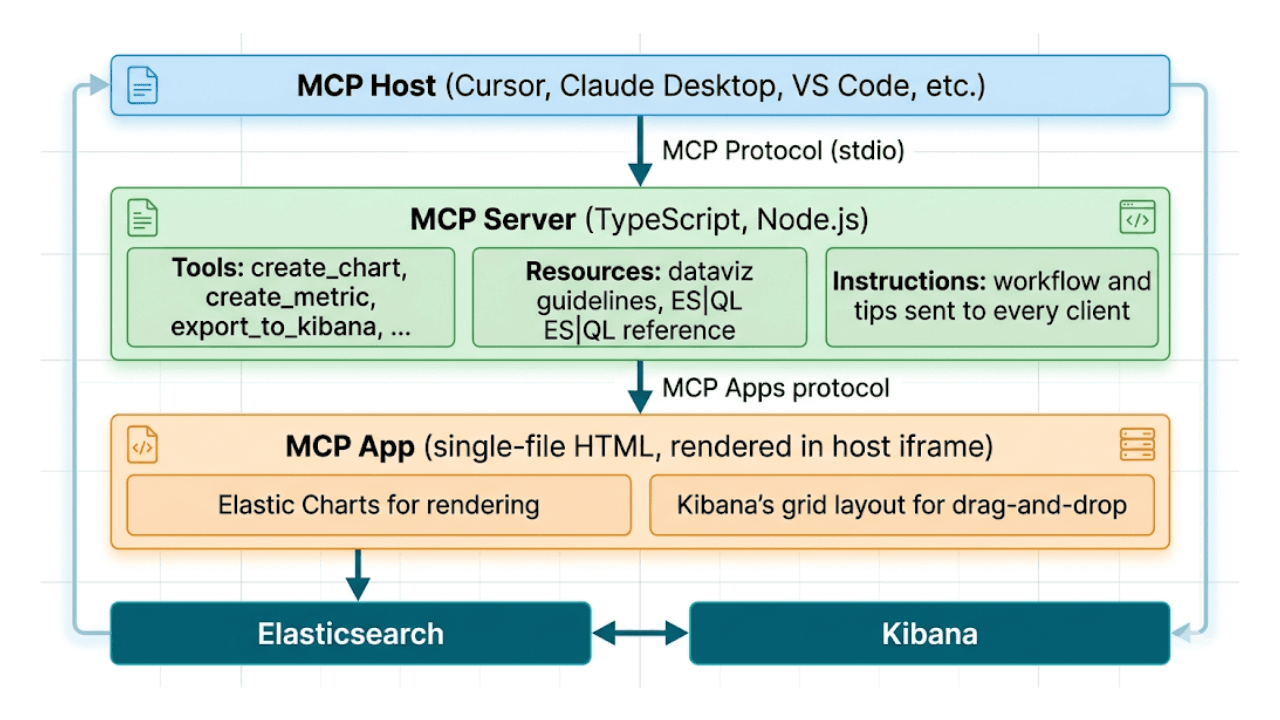
Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.