Hoy lanzamos jina-embeddings-v3, el primer modelo de base de búsqueda de Jina que estará disponible en Model Garden de Gemini Enterprise Agent Platform como un modelo de socio autodesplegable. El autodespliegue significa que el modelo se ejecuta en instancias de GPU dentro de tu proyecto de Google Cloud y Virtual Private Cloud (VPC). Sin llamadas API externas, sin medición por token, sin límites de velocidad.
Con esta integración, los usuarios de Elasticsearch obtienen una nueva opción de despliegue que mantiene los datos dentro de su perímetro de seguridad, ofrece costos previsibles de infraestructura y se ejecuta de forma nativa en Google Cloud. Al mismo tiempo, el ecosistema más amplio de Google Cloud obtiene acceso a los modelos de búsqueda y recuperación de última generación de Jina, diseñados específicamente para este fin.
Esta es la primera fase de una implementación más amplia. Junto con los modelos que vienen después, la selección formará una pila de recuperación completa: incrusta tus datos, incrusta búsquedas, recupera y reclasifica candidatos, y extiende la búsqueda a imágenes con incrustaciones multimodales, todo en la infraestructura que controles. Puedes empezar hoy mismo con jina-embeddings-v3, el modelo que ya impulsa las pipelines de búsqueda de producción en todo el ecosistema de Elasticsearch a través de Elastic Inference Service (EIS).
| Modelo | Tipo | Parámetros | Capacidad clave | Estado en el Model Garden |
|---|---|---|---|---|
| `jina-embeddings-v3` | Incrustación de texto | 572M | Un caballo de batalla multilingüe probado, con un contexto de 8000, una salida de 1024 dimensiones, truncable a 32 | Disponible ahora |
| `jina-embeddings-v5-text-small` | Incrustación de texto | 677M | Multilingüe sub-1B de última generación, contexto de 32 000, una salida de 1024 dimensiones, truncable a 32 | Próximamente |
| `jina-embeddings-v5-text-nano` | Incrustación de texto | 239M | El mejor de su categoría con menos de 500 millones de parámetros, contexto de 8000, una salida de 768 dimensiones, truncable a 32 | Próximamente |
| `jina-reranker-v3` | Reclasificador | 600M | Reclasificador por lista, contexto de 131K, hasta 64 documentos | Próximamente |
| `jina-clip-v2` | Incrustación multimodal | 900 millones | Texto e imagen en un espacio compartido, 89 idiomas y un contexto de texto de 8000, imágenes de 512 × 512 | Próximamente |
Todos los modelos se ejecutan en una sola NVIDIA L4 (24 GB), el nivel de GPU más rentable de Google Cloud. La mayoría de los otros modelos de incrustación en Model Garden de Google Cloud requieren un A100 80 GB o H100, aproximadamente tres veces el costo de instancia por hora incluso antes de comenzar a contar tokens.
No se requiere licencia comercial adicional cuando se despliega a través de Vertex AI.
¿Por qué Model Garden?
¿Por qué desplegar a través de Model Garden en lugar de usar una API? Se reduce a tres cosas: control, costo y contexto.
Tus datos nunca salen de casa
Lo que más atrae a la mayoría de los desarrolladores es la arquitectura de autodespliegue. Cuando despliegas un modelo de Jina a través de Model Garden, los pesos se ejecutan en instancias de GPU dentro de tu propio proyecto de Google Cloud y tu propia VPC. Esto supone un cambio revolucionario para cualquiera que trabaje en sectores donde la seguridad de los datos es una preocupación, como las finanzas o la salud. Como no hay llamadas externas a API, tus datos confidenciales permanecen dentro de tu perímetro de seguridad.
Escalado con predicción
En lugar de pagar cada vez que incrustas una oración o reclasificas un documento, pagas un costo fijo por hora de instancia. Y dado que todos los modelos de Jina pueden ejecutarse en una sola NVIDIA L4, el nivel de GPU más asequible de Google Cloud, la barrera de entrada es baja. Tanto si procesas mil solicitudes como mil millones, tu factura de infraestructura se mantiene previsible. Este sistema te recompensa por aumentar tu tráfico en lugar de cobrarte impuestos por ello.
Todo bajo un mismo techo
Si tus datos ya están en Elasticsearch en Google Cloud, BigQuery o almacenamiento en el cloud, tiene sentido mantener tus motores de inferencia cerca. Al desplegar a través de Model Garden, los modelos de búsqueda de Jina heredan todas las características empresariales que ya estás utilizando: gestión de identidad y acceso (IAM) para el control de acceso, facturación unificada en tu factura existente de Google Cloud, y la capacidad de conectarse a las pipelines de Vertex AI para flujos de trabajo de operaciones de machine learning (MLOps).
Si bien la API de Jina AI Cloud y Elastic Cloud permiten escalar rápidamente ante picos de tráfico o integrarse con flujos de búsqueda ya existentes, Model Garden resulta la mejor opción para aplicaciones empresariales que exigen altos estándares de seguridad de datos y costos predecibles a gran escala. Elastic quiere adaptarse a tus necesidades.
Modelos de Jina AI
jina-embeddings-v3
Nuestro probado modelo de incrustación multilingüe con 572 millones de parámetros y 8000 de contexto de tokens. Obtiene una puntuación de 65,5 en el Massive Text Embedding Benchmark (MTEB) en inglés. Admite cinco adaptadores de adaptación de rango bajo (LoRA) específicos de la tarea (consulta de recuperación/pasaje, coincidencia de texto, clasificación, agrupar) y truncamiento de Matryoshka de 1024 a 64 dimensiones. Ya está ampliamente adoptado en todo el ecosistema de Elasticsearch a través de EIS.
Estamos liderando con la v3 porque muchos sistemas de producción ya dependen de ella. Si estás migrando una pipeline basado en la v3 a Google Cloud, ahora puedes ejecutar el mismo modelo de forma nativa sin tener que cambiar las dimensiones de incrustación ni volver a indexar.
jina-embeddings-v5-text (pequeño y nano)
Nuestros modelos de incrustación de texto de quinta generación, lanzados en febrero de 2026, logran un rendimiento de primer nivel, y compiten con modelos muchas veces más grandes.
v5-text-small (677 millones) obtiene una puntuación de 67,0 en el conjunto de pruebas MTEB multilingües (MMTEB), que abarca 131 tareas de nueve tipos de tareas, y 71,7 en el MTEB en inglés. Es el modelo de incrustación multilingüe sub-1B más potente en la tabla de clasificación de MTEB.
v5-text-nano (239 millones) obtiene una puntuación de 65,5 en MMTEB. Ningún otro modelo con menos de 500 millones de parámetros alcanza este nivel. Con menos de la mitad del tamaño que la mayoría de modelos comparables, es la elección natural para despliegues en el edge y sensibles a la latencia.
Ambos modelos son compatibles con:
- Cuatro adaptadores LoRA específicos para cada tarea: recuperación, coincidencia de texto, clasificación, agrupación. Se selecciona un adaptador apropiado a través del parámetro
tasken el momento de la inferencia. - Truncamiento de dimensiones de Matryoshka: reduce las dimensiones de incrustación de 1024 (o 768 para nano) a 32. La pérdida de calidad es mínima con un truncamiento moderado (p. ej., 256 dimensiones). Reducir las dimensiones a la mitad supone, aproximadamente, reducir el espacio de almacenamiento a la mitad.
- Cuantización binaria: comprime incrustaciones de 1024 dimensiones de 2 KB a 128 bytes mediante binarización. Un entrenamiento especial hace que esta compresión tenga pérdidas mínimas.
- Multilingüe: 119 idiomas (pequeño) y 93 (nano).
jina-reranker-v3
Un reclasificador multilingüe de listas de 0,6 mil millones de parámetros construido con una arquitectura de interacción de vanguardia. La consulta y hasta 64 coincidencias candidatas se ingresan en una única ventana de contexto de 131 000 tokens, y el modelo realiza una comparación entre documentos antes de la puntuación. El reclasificador v3 de Jina alcanza un nDCG@10 de 61,94 en BEIR, lo que supera al modelo que tiene un tamaño seis veces menor. Esto difiere fundamentalmente de los reclasificadores puntuales, que puntúan cada documento de forma aislada, lo que produce mejores resultados, especialmente para la recuperación de pasajes de documentos individuales.
jina-clip-v2
Un modelo de incrustación multimodal y multilingüe de 0,9 mil millones que mapea texto e imágenes en un espacio compartido de 1024 dimensiones. Es compatible con:
- 89 idiomas para la recuperación de imágenes de texto.
- Resolución de imagen de 512 × 512.
- Entrada de texto de 8000 tokens.
- Truncamiento Matryoshka de 1024 a 64 dimensiones para ambas modalidades.
Altamente competitivo en pruebas comparativas de conversión de imagen a texto, incluidas las tareas multilingües.
Primeros pasos
Jina Embeddings v3 está disponible en Model Garden hoy. Aquí te explicamos cómo ponerlo en marcha.
Necesitas un proyecto de Google Cloud con la API de Vertex AI habilitada y suficiente cuota de GPU para al menos una instancia g2-standard-8 (NVIDIA L4). Si eres nuevo en Google Cloud, empieza por la guía de configuración.
La página Model Garden para las incrustaciones v3 de Jina te guía por todo el flujo: sube el modelo, crea un endpoint, elige el tipo de máquina y despliega. Ábrela en tu propio proyecto y sigue los pasos guiados. Las máquinas A100 y H100 también están disponibles donde la región y la cuota lo permitan, pero L4 es todo lo que necesitas para comenzar.
Desde el clic hasta la primera incrustación, todo el proceso toma unos minutos.
Lo que viene después
Las incrustaciones v3 de Jina son el punto de partida. En las próximas semanas, llevaremos el resto de la pila de recuperación de Jina a Model Garden: incrustaciones de texto v5 (pequeñas y nano), jina-reranker-v3 y jina-clip-v2 para búsqueda multimodal. Todos se ejecutarán en una sola GPU L4 con el mismo modelo de autodespliegue.
Contenido relacionado

11 de mayo de 2026
Un índice, todos los medios: presentamos jina-embeddings-v5-omni
jina-embeddings-v5-omni te permite incrustar texto, imágenes, video y audio en un único índice de Elasticsearch y realizar búsquedas en todos a la vez.

23 de febrero de 2026
jina-embeddings-v5-text: incrustaciones de texto compactas y de última generación para aplicaciones de búsqueda e inteligentes
Introducimos los modelos jina-embeddings-v5-text, lo que incluye jina-embeddings-v5-text-small y jina-embeddings-v5-text-nano, y explicamos cómo usar estos modelos de incrustación multilingüe a través del Elastic Inference Service (EIS).
1 de enero de 2026
Introducción a los modelos de Jina, su funcionalidad y usos en Elasticsearch
Explora las incrustaciones multimodales de Jina, Reranker v3 y los modelos de incrustación semántica, y aprende cómo usarlos de forma nativa en Elasticsearch.

22 de mayo de 2026
Kibana reduce el tiempo de carga del dashboard hasta en un 25 %: esta es la estrategia de sondeo que hay detrás
Descubre cómo Kibana usa el sondeo continuo y la detección de HTTP/2 en el navegador para reducir los tiempos de carga del dashboard hasta en un 25 %, con una transición automática a HTTP/1 en caso de que no sea posible.
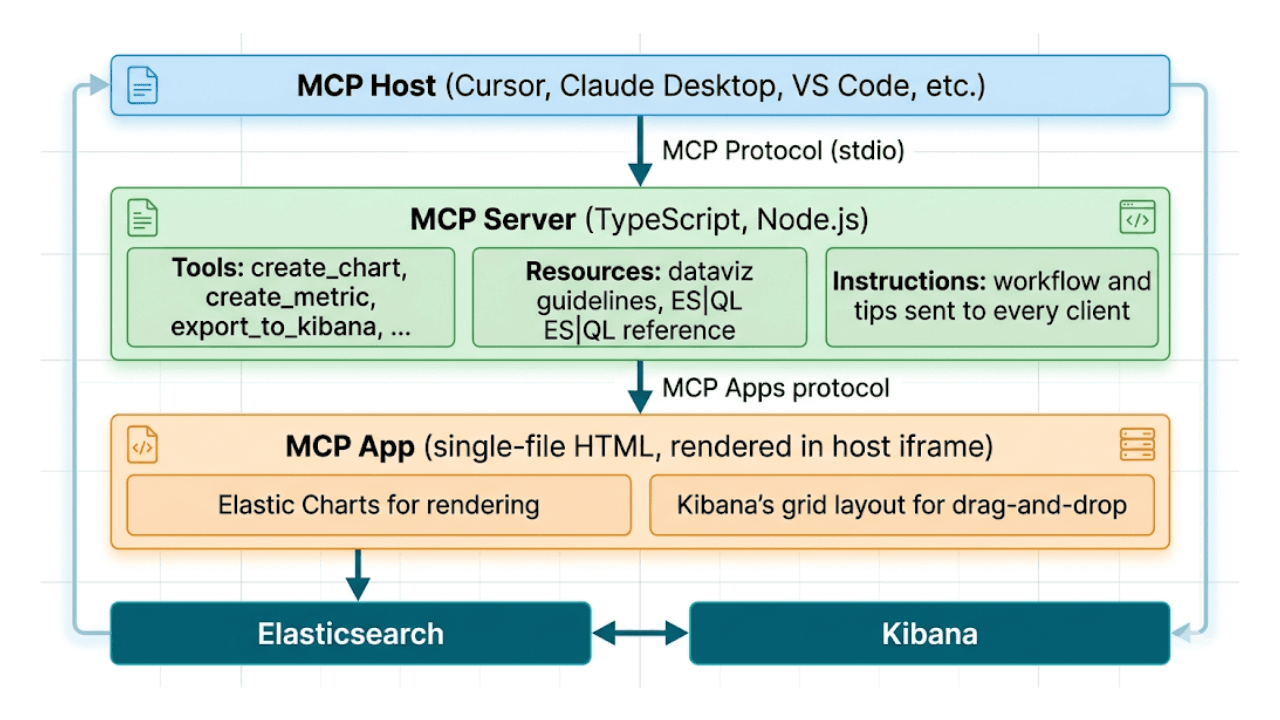
Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.