오늘 저희는 자체 배포 가능한 파트너 모델로서 Gemini Enterprise Agent Platform Model Garden에서 사용할 수 있는 최초의 Jina 검색 기반 모델인 jina-embeddings-v3를 출시합니다. 자체 배포는 모델이 Google Cloud 프로젝트 및 가상 프라이빗 클라우드(VPC) 내의 GPU 인스턴스에서 실행된다는 의미입니다. 외부 API 호출, 토큰당 사용량 추적, 요금 제한이 없습니다.
이 통합을 통해 Elasticsearch 사용자는 데이터를 보안 경계 내에 유지하고, 예측 가능한 인프라 비용을 제공하며, Google Cloud에서 기본적으로 실행되는 새로운 배포 옵션을 얻게 됩니다. 동시에 더 광범위한 Google Cloud 에코시스템은 Jina의 특수 목적에 맞게 구축된 최첨단 검색 및 검색 모델에 액세스할 수 있습니다.
이것은 더 광범위한 출시의 첫 번째 단계입니다. 다음에 출시될 모델과 함께 완벽한 검색 스택을 구성하게 될 것입니다. 데이터를 임베드하고, 쿼리를 임베드하고, 후보를 검색하고 순위를 재조정하고, 멀티모달 임베딩을 통해 이미지로 검색을 확장하는 모든 작업을 사용자가 제어하는 인프라에서 수행할 수 있습니다. 지금 바로 jina-embeddings-v3 모델로 시작할 수 있습니다. 이 모델은 이미 Elastic Inference Service(EIS)를 통해 Elasticsearch 에코시스템 전반의 프로덕션 검색 파이프라인을 지원하고 있습니다.
| 모델 | 유형 | 매개변수 | 핵심 역량 | Model Garden의 상태 |
|---|---|---|---|---|
| `jina-embeddings-v3` | 텍스트 임베딩 | 572M | 검증된 다국어 작업 도구, 8K 컨텍스트, 1,024차원 출력, 32까지 축소 가능 | 사용 가능 |
| `jina-embeddings-v5-text-small` | 텍스트 임베딩 | 677M | 최첨단 10억 미만 다국어 지원, 32K 컨텍스트, 1024차원 출력, 32까지 축소 가능 | 곧 출시 예정 |
| `jina-embeddings-v5-text-nano` | 텍스트 임베딩 | 239M | 동급 최고의 500M 미만 매개변수, 8K 컨텍스트, 768차원 출력, 32까지 축소 가능 | 곧 출시 예정 |
| `jina-reranker-v3` | 순위 재지정기 | 600M | 목록별 순위 재조정기, 131K 컨텍스트, 최대 64개 문서 | 곧 출시 예정 |
| `jina-clip-v2` | 멀티모달 임베딩 | 900M | 공유 공간의 텍스트 + 이미지, 89개 언어, 8K 텍스트 컨텍스트, 512×512 이미지 | 곧 출시 예정 |
모든 모델은 Google Cloud에서 가장 비용 효율적인 GPU 계층인 단일 NVIDIA L4(24GB)로 실행됩니다. Google Cloud Model Garden의 다른 대부분의 임베딩 모델은 A100 80GB 또는 H100을 필요로 하는데, 이는 토큰 계산을 시작하기도 전에 시간당 인스턴스 비용의 약 3배에 달합니다.
Vertex AI를 통해 배포할 경우 추가적인 상업용 라이선스가 필요하지 않습니다.
Model Garden인 이유는 무엇인가요?
API를 직접 호출하는 대신 Model Garden을 통해 배포해야 하는 이유는 무엇일까요? 제어, 비용, 컨텍스트 세 가지로 요약할 수 있습니다.
데이터는 절대 외부로 유출되지 않습니다
대부분의 개발자에게 가장 큰 매력은 자체 배포 아키텍처입니다. Model Garden을 통해 Jina 모델을 배포하면 가중치는 자체 Google Cloud 프로젝트 및 자체 VPC 내의 GPU 인스턴스에서 실행됩니다. 이는 금융이나 의료와 같이 데이터 보안에 대한 우려가 있는 산업에 종사하는 모든 사람에게 획기적인 변화입니다. 외부 API 호출이 없으므로 민감한 데이터는 보안 경계 내에 안전하게 보관됩니다.
예측을 통한 확장
문장을 삽입하거나 문서 순위를 다시 매길 때마다 비용을 지불하는 대신 시간당 고정 인스턴스 비용을 지불하면 됩니다. 또한 모든 Jina 모델은 Google Cloud에서 가장 저렴한 GPU 티어인 단일 NVIDIA L4에서 실행할 수 있으므로 진입 장벽이 낮습니다. 요청을 천 건 처리하든 십억 건 처리하든, 인프라 비용은 예측 가능합니다. 이는 트래픽 증가에 대해 세금을 부과하는 것이 아니라 실제로 보상을 제공하는 설정입니다.
모든 것을 한 지붕 아래에서
데이터가 이미 Google Cloud, BigQuery 또는 Cloud Storage의 Elasticsearch에 있는 경우, 추론 엔진을 가까운 곳에 두는 것이 좋습니다. Model Garden을 통해 배포하면 Jina 검색 기반 모델은 액세스 제어를 위한 ID 및 액세스 관리(IAM), 기존 Google Cloud 인보이스 통합 청구, 머신 러닝 작업(MLOps) 워크플로우를 위한 Vertex AI 파이프라인에 연결하는 기능 등 이미 사용 중인 모든 엔터프라이즈 기능을 그대로 이어받게 됩니다.
Jina AI Cloud API와 Elastic Cloud는 폭증하는 트래픽이나 기존 검색 워크플로우에 가장 빠른 경로를 제공하는 반면, Model Garden은 엄격한 데이터 보안과 대규모 환경에서도 예측 가능한 비용이 필요한 엔터프라이즈 애플리케이션에 이상적입니다. Elastic은 고객이 필요로 하는 곳에서 서비스를 제공합니다.
Jina AI 모델
jina-embeddings-v3
당사의 입증된 다국어 임베딩 모델은 5억 7,200만 개의 매개변수와 8K 토큰 컨텍스트를 갖추고 있습니다. 대량 텍스트 임베딩 벤치마크(MTEB) 영어에서 65.5점을 받았습니다. 5개의 작업별 저순위 적응(LoRA) 어댑터(검색 쿼리/지문, 텍스트 매칭, 분류, 클러스터링)와 1024차원에서 64차원의 마트료시카 절단을 지원합니다. 이미 EIS를 통해 Elasticsearch 에코시스템 전반에 걸쳐 널리 채택되었습니다.
당사는 많은 생산 시스템이 이미 v3에 의존하고 있기 때문에 v3를 선도하고 있습니다. v3 기반 파이프라인을 Google Cloud로 마이그레이션하는 경우 이제 임베딩 차원을 변경하거나 색인을 다시 생성하지 않고도 동일한 모델을 기본적으로 실행할 수 있습니다.
jina-embeddings-v5-text(소형 및 나노)
2026년 2월에 출시된 5세대 텍스트 임베딩 모델은 그보다 몇 배 큰 모델과 경쟁하여 최고 수준의 성능을 달성합니다.
v5-text-small (677M) 9개 작업 유형의 131개 작업을 포괄하는 다국어 MTEB(MMTEB) 벤치마크 제품군에서 67.0점, MTEB 영어 벤치마크에서 71.7점을 기록했습니다. MTEB 리더보드에서 가장 강력한 10억 개 미만 매개변수의 다국어 임베딩 모델입니다.
v5-text-nano (239M) MMTEB에서 65.5점을 받았습니다. 5억 개 미만의 매개변수를 가진 다른 모델은 이 수준에 도달하지 못합니다. 대부분의 유사 모델보다 크기가 절반도 안 되기 때문에 엣지 환경 및 지연 시간에 민감한 배포에 가장 적합한 선택입니다.
두 모델 모두 지원합니다:
- LoRA 어댑터는 검색, 텍스트 매칭, 분류, 클러스터링의 네 가지 작업별 어댑터로 구성됩니다 . 추론 시
task매개변수를 통해 적절한 어댑터를 선택합니다. - 마트료시카 차원 축소: 임베딩 차원을 1024(나노의 경우 768)에서 32로 줄입니다. 품질 손실은 중간 정도의 잘라내기(예: 256차원)에서 최소화됩니다. 차원을 절반으로 줄이면 저장 공간도 대략 절반으로 줄어듭니다.
- 이진 양자화: 1,024차원 임베딩을 이진 양자화를 통해 2KB에서 128바이트로 압축합니다. 특별한 훈련을 통해 압축 손실을 최소화합니다.
- 다국어: 119개 언어(소형) 및 93개 언어(나노).
jina-reranker-v3
최신이지만 느리지 않은 인터랙션 아키텍처를 사용하여 구축된 0.6B 매개변수 다국어 목록형 재랭커입니다. 쿼리와 최대 64개의 후보 매칭이 하나의 131K 토큰 컨텍스트 창에 입력되며, 모델은 점수 매기기 전에 문서 간 비교를 수행합니다. Jina Reranker v3는 BEIR에서 61.94 nDCG@10을 기록하며, 크기가 6배 작아 모델보다 더 좋은 성능을 보입니다. 이는 각 문서별로 점수를 매기는 점수별 순위 재지정기와는 근본적으로 다르며, 특히 단일 문서에서 지문 검색에 더 좋은 결과를 냅니다.
jina-clip-v2
텍스트와 이미지를 1024차원의 공유 공간에 Maps하는 0.9B 크기의 멀티모달, 다국어 임베딩 모델입니다. 다음을 지원합니다.
- 텍스트-이미지 검색을 위한 89개 언어.
- 512×512 이미지 해상도.
- 8K 토큰 텍스트 입력.
- 두 양식 모두 1024에서 64차원으로 마트료시카 잘라내기.
다국어 작업을 포함한 이미지-텍스트 벤치마크에서 높은 경쟁력을 자랑합니다.
시작하기
Jina Embeddings v3가 오늘 Model Garden에 공개되었습니다. 작동시키는 방법은 다음과 같습니다.
Vertex AI API가 활성화된 Google Cloud 프로젝트가 필요하며 최소 하나의 g2-standard-8 인스턴스(NVIDIA L4)를 위한 충분한 GPU 할당량이 있어야 합니다. Google Cloud를 처음 사용하는 경우 설정 가이드부터 시작하세요.
Jina Embeddings v3의 Model Garden 페이지는 모델을 업로드하고, 엔드포인트를 생성하며, 머신 유형을 선택하고, 배포하는 전체 흐름을 안내합니다. 자신의 프로젝트에서 열고 안내된 단계를 따르세요. 지역과 할당량이 허용하는 곳에서는 A100과 H100 머신도 사용할 수 있지만 시작하려면 L4만 있으면 됩니다.
클릭부터 첫 임베딩까지 전체 과정은 몇 분이면 완료됩니다.
다음 단계
Jina Embeddings v3가 출발점입니다. 향후 몇 주 안에 Model Garden에 Jina 검색 스택의 나머지 부분인 v5 텍스트 임베딩(소형 및 나노), jina-reranker-v3, 그리고 멀티모달 검색을 위한 jina-clip-v2를 추가할 예정입니다. 모두 동일한 자체 배포 모델의 단일 L4 GPU에서 실행됩니다.
관련 콘텐츠

2026년 5월 11일
모든 미디어, 단 하나의 인덱스: jina-embeddings-v5-omni
jina-embeddings-v5-omni를 사용하면 텍스트, 이미지, 동영상 및 오디오를 단일 Elasticsearch 인덱스에 임베드하고 모든 항목을 한 번에 쿼리할 수 있습니다.

2026년 2월 23일
jina-embeddings-v5-text: 검색 및 지능형 애플리케이션을 위한 컴팩트한 최신 텍스트 임베딩
jina-embeddings-v5-text 모델을 소개하고, jina-embeddings-v5-text-small 및 jina-embeddings-v5-text-nano를 비롯한 다국어 임베딩 모델을 Elastic Inference Service(EIS)를 통해 사용하는 방법을 설명합니다.
Jina 모델, 그 기능 및 Elasticsearch에서의 사용에 대한 소개
Jina 멀티모달 임베딩, Reranker v3 및 시맨틱 임베딩 모델을 탐색하고, 이를 Elasticsearch에서 기본적으로 사용하는 방법을 알아보세요.

2026년 5월 22일
Kibana 대시보드 로딩 속도 최대 25% 단축, 그 뒤에 숨겨진 폴링 최적화 전략
Kibana가 어떻게 지속적 폴링과 브라우저 단 HTTP/2 감지 기술을 활용해 대시보드 로딩 시간을 최대 25%까지 줄였는지, 그리고 HTTP/1 환경으로의 자동 폴백 기능은 어떻게 작동하는지 알아봅니다.
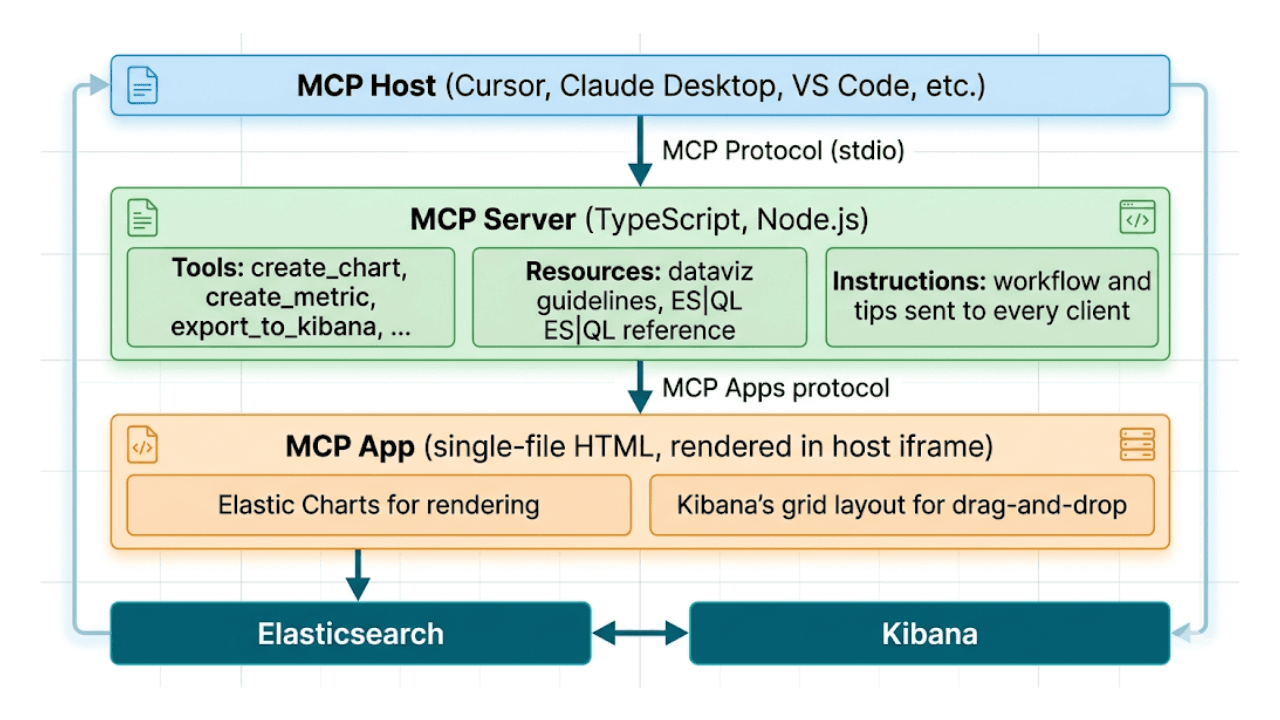
그리지 말고 설명하세요: MCP와 ES|QL을 통한 AI 네이티브 Kibana 대시보드
프롬프트부터 대시보드까지, ES|QL 쿼리를 작성하고, 대화형 차트를 생성하며, 모든 기능을 갖춘 대시보드를 Kibana로 직접 내보내는 오픈 소스 MCP 애플리케이션인 example-mcp-dashbuilder를 사용해 자연어로 Kibana 대시보드를 구축하는 방법에 대해 알아보세요.