Aujourd'hui, nous lançons jina-embeddings-v3, le premier modèle de fondation de recherche Jina disponible sur Model Garden de Gemini Entreprise Agent Platform en tant que modèle partenaire autodéployable. L'autodéploiement signifie que le modèle s'exécute sur des instances GPU au sein de votre projet Google Cloud et de votre cloud privé virtuel (VPC). Aucun appel externe d'API, pas de comptage par token, pas de limitations de taux.
Grâce à cette intégration, les utilisateurs d'Elasticsearch bénéficient d'une nouvelle option de déploiement qui maintient les données à l'intérieur de leur périmètre de sécurité, offre des coûts d'infrastructure prévisibles et s'exécute nativement sur Google Cloud. Dans le même temps, l'écosystème Google Cloud élargi accède aux modèles de recherche et de récupération de pointe spécialement conçus par Jina.
Il s'agit de la première étape d'un déploiement plus large. Avec les modèles à venir, la gamme formera une pile de récupération complète : intégration de vos données, intégration des requêtes, récupération et reclassement des candidats, et extension de la recherche aux images avec des embeddings multimodaux, le tout sur une infrastructure que vous contrôlez. Vous pouvez commencer dès aujourd'hui par jina-embeddings-v3, le modèle qui alimente déjà les pipelines de recherche de production au sein de l'écosystème Elasticsearch via Elastic Inference Service (EIS).
| Modèle | Type | Paramètres | Capacité principale | Statut sur Model Garden |
|---|---|---|---|---|
| `jina-embeddings-v3` | Embedding textuel | 572M | Modèle multilingue éprouvé, contexte 8K, sortie 1 024 dimensions, tronquable à 32 | Disponible dès à présent |
| `jina-embeddings-v5-text-small` | Embedding textuel | 677M | Technologie multilingue sub-1B de pointe, contexte 32K, sortie 1 024 dimensions, tronquable à 32 | Bientôt disponible |
| `jina-embeddings-v5-text-nano` | Embedding textuel | 239M | Meilleur de sa catégorie pour moins de 500 millions de paramètres, contexte 8K, sortie 768 dimensions, tronquable à 32 | Bientôt disponible |
| `jina-reranker-v3` | Reranker | 600M | Reranker par liste, contexte 131K, jusqu'à 64 documents | Bientôt disponible |
| `jina-clip-v2` | Embedding multimodal | 900M | Texte et image dans un espace partagé, 89 langues, contexte textuel 8K, images 512×512 | Bientôt disponible |
Chaque modèle s'exécute sur un seul GPU NVIDIA L4 (24 Go), le niveau de GPU le plus économique sur Google Cloud. La plupart des autres modèles embarqués sur Google Cloud Model Garden nécessitent un A100 de 80 Go ou un H100, soit environ trois fois le coût horaire de l'instance, avant même de prendre en compte les jetons.
Aucune licence commerciale supplémentaire n'est requise lorsque le système est déployé via Vertex AI.
Pourquoi Model Garden ?
Pourquoi déployer via Model Garden au lieu d'appeler une API ? Tout se résume à trois éléments : le contrôle, le coût et le contexte.
Vos données ne quittent jamais leur emplacement
Le principal atout pour la plupart des développeurs réside dans l'architecture d'autodéploiement. Lorsque vous déployez un modèle Jina via Model Garden, les poids sont exécutés sur des instances GPU au sein de votre propre projet Google Cloud et de votre propre VPC. C'est un avantage considérable pour tous ceux qui travaillent dans des secteurs où la sécurité des données est primordiale, comme la finance ou la santé. L'absence d'appels API externes garantit que vos données sensibles restent protégées au sein de votre périmètre de sécurité.
Scaling avec prédiction
Au lieu de payer à chaque intégration de phrase ou reclassement de document, vous bénéficiez d'un tarif horaire fixe. Chaque modèle Jina pouvant s'exécuter sur un seul processeur NVIDIA L4, le niveau de GPU le plus abordable de Google Cloud, l'accès à cette solution est très facile. Que vous traitiez mille requêtes ou un milliard, votre facture d'infrastructure reste prévisible. Ce système vous récompense pour la croissance de votre trafic au lieu de vous pénaliser.
Tout sous un même toit
Si vos données sont déjà stockées dans Elasticsearch sur Google Cloud, BigQuery ou Cloud Storage, il est judicieux de conserver vos moteurs d'inférence à proximité. En déployant vos modèles de recherche Jina via Model Garden, vous bénéficiez de toutes les fonctionnalités d'entreprise que vous utilisez déjà : gestion des identités et des accès (IAM) pour le contrôle d'accès, facturation unifiée sur votre facture Google Cloud existante et intégration possible aux pipelines de Vertex AI pour les workflows d'opérations de machine learning (MLOps).
Si l'API Jina AI Cloud et Elastic Cloud offrent la solution la plus rapide pour les pics de trafic ou les workflows de recherche existants, Model Garden est idéal pour les applications d'entreprise exigeant une sécurité des données rigoureuse et des coûts prévisibles à grande échelle. Elastic s'adapte à vos besoins.
Modèles Jina AI
jina-embeddings-v3
Notre modèle d'embedding multilingue éprouvé, doté de 572 millions de paramètres et d'un contexte de 8 000 tokens, obtient un score de 65,5 à l'évaluation MTEB (Massive Text Embedding Benchmark) en anglais. Il prend en charge cinq adaptateurs LoRA (Low-Rank Adaptation) spécifiques à chaque tâche (requête/récupération par passage, correspondance de texte, classification, clustering) et la troncature Matryoshka de 1 024 à 64 dimensions. Déjà largement adopté au sein de l'écosystème Elasticsearch via EIS.
Nous avons choisi la v3 parce que de nombreux systèmes de production en dépendent déjà. Si vous migrez un pipeline basé sur la v3 vers Google Cloud, vous pouvez désormais exécuter le même modèle en mode natif sans modifier vos dimensions d'embedding ni réindexer.
jina-embeddings-v5-text (small et nano)
Nos modèles d'embedding textuel de cinquième génération, publiés en février 2026, atteignent des performances de pointe, concurrençant des modèles bien plus volumineux.
v5-text-small (677M) obtient un score de 67,0 sur l'ensemble de benchmarks MMTEB (Multilingual MTEB), qui comprend 131 tâches réparties en neuf catégories, et de 71,7 sur le benchmark MTEB en anglais. C'est le modèle d'intégration multilingue sub-1B le plus puissant du classement MTEB.
v5-text-nano (239M) obtient un score de 65,5 au MMTEB. Aucun autre modèle de moins de 500 millions de paramètres n'atteint ce niveau. Avec moins de la moitié de la taille de la plupart des modèles comparables, c'est le choix naturel pour les déploiements en périphérie et sensibles à la latence.
Les deux modèles prennent en charge :
- Quatre adaptateurs LoRA spécifiques à la tâche : récupération, correspondance de texte, classification, clustering. Sélection d'un adaptateur approprié via le paramètre
taskau moment de l'inférence. - Troncature de la dimension Matryoshka : réduction des dimensions d'intégration de 1024 (ou 768 pour nano) à 32. La perte de qualité est minime pour une réduction modérée (par exemple, 256 dimensions). Diviser les dimensions par deux divise approximativement par deux l'espace de stockage.
- Quantification binaire : Compression des enregistrements 1024-dim de 2 Ko à 128 octets avec la binarisation. Un entraînement spécial permet de limiter les pertes liées à cette compression.
- Multilingue : 119 langues (small) et 93 (nano).
jina-reranker-v3
Un reranker multilingue par liste de 0,6 milliard de paramètres construit selon une architecture basée sur la dernière interaction (mais pas la plus tardive). La requête et jusqu'à 64 correspondances candidates sont insérées dans une fenêtre de contexte unique de 131K jetons, et le modèle effectue une comparaison interdocuments avant l'attribution du score. Jina Reranker v3 atteint un nDCG@10 de 61,94 sur BEIR, surpassant ainsi un modèle six fois plus petit. Cette approche diffère fondamentalement des rerankers ponctuels qui évaluent chaque document individuellement et offre de meilleurs résultats, notamment pour la récupération par passages dans des documents uniques.
jina-clip-v2
Un modèle d'embedding multimodal et multilingue de 0,9 milliard de paramètres qui mappe le texte et les images dans un espace partagé à 1024 dimensions. Il prend en charge :
- 89 langues pour la récupération de texte-image.
- Résolution d'image 512×512.
- Entrée texte de 8K jetons.
- Troncature de Matryoshka de 1024 à 64 dimensions pour les deux modalités.
Très compétitif sur les benchmarks de conversion image vers texte, y compris les tâches multilingues.
Premiers pas
Jina Embeddings v3 est disponible aujourd’hui sur Model Garden. Voici comment l'installer.
Vous avez besoin d'un projet Google Cloud avec l'API Vertex AI activée et d'un quota de GPU suffisant pour au moins une instance g2-standard-8 (NVIDIA L4). Si vous êtes nouveau sur Google Cloud, commencez par le guide de configuration.
La page Model Garden pour Jina Embeddings v3 vous guide tout au long du processus : importez le modèle, créez un point de terminaison, choisissez votre type de machine et déployez. Ouvrez-le dans votre propre projet et suivez les étapes guidées. Les machines A100 et H100 sont également disponibles lorsque la région et le quota le permettent, mais L4 est tout ce dont vous avez besoin pour commencer.
De clic à première intégration, l'ensemble du processus prend quelques minutes.
Ce qui vient ensuite
Jina Embeddings v3 est le point de départ. Dans les semaines à venir, nous ajouterons le reste de la pile de récupération Jina à Model Garden : les embeddings textuels v5 (small et nano), jina-reranker-v3, et jina-clip-v2 pour la recherche multimodale. Tous fonctionneront sur un seul GPU L4 avec le même modèle de déploiement automatique.
Pour aller plus loin

11 mai 2026
Un seul index, tous les médias : présentation de jina-embeddings-v5-omni
jina-embeddings-v5-omni vous permet d’intégrer du texte, des images, des vidéos et de l’audio dans un seul index Elasticsearch, et d’effectuer des requêtes sur tous ces éléments à la fois.

23 février 2026
jina-embeddings-v5-text : modèles d’embeddings textuels compacts et de pointe pour la recherche et les applications intelligentes
Présentation des modèles jina-embeddings-v5-text, dont jina-embeddings-v5-text-small et jina-embeddings-v5-text-nano, ainsi que de leur utilisation en tant que modèles d’embeddings multilingues via Elastic Inference Service (EIS).
1 janvier 2026
Présentation des modèles Jina, de leurs fonctionnalités et de leurs cas d’usage dans Elasticsearch
Explorez les embeddings multimodaux Jina, Reranker v3 et les modèles d'embedding sémantique, et découvrez comment les utiliser en mode natif dans Elasticsearch.

22 mai 2026
Kibana réduit le temps de chargement des tableaux de bord jusqu'à 25 %. Voici la stratégie d'interrogation qui se cache derrière
Découvrez comment Kibana utilise l'interrogation continue et la détection HTTP/2 côté navigateur pour réduire les temps de chargement des tableaux de bord jusqu'à 25 %, avec repli automatique sur HTTP/1.
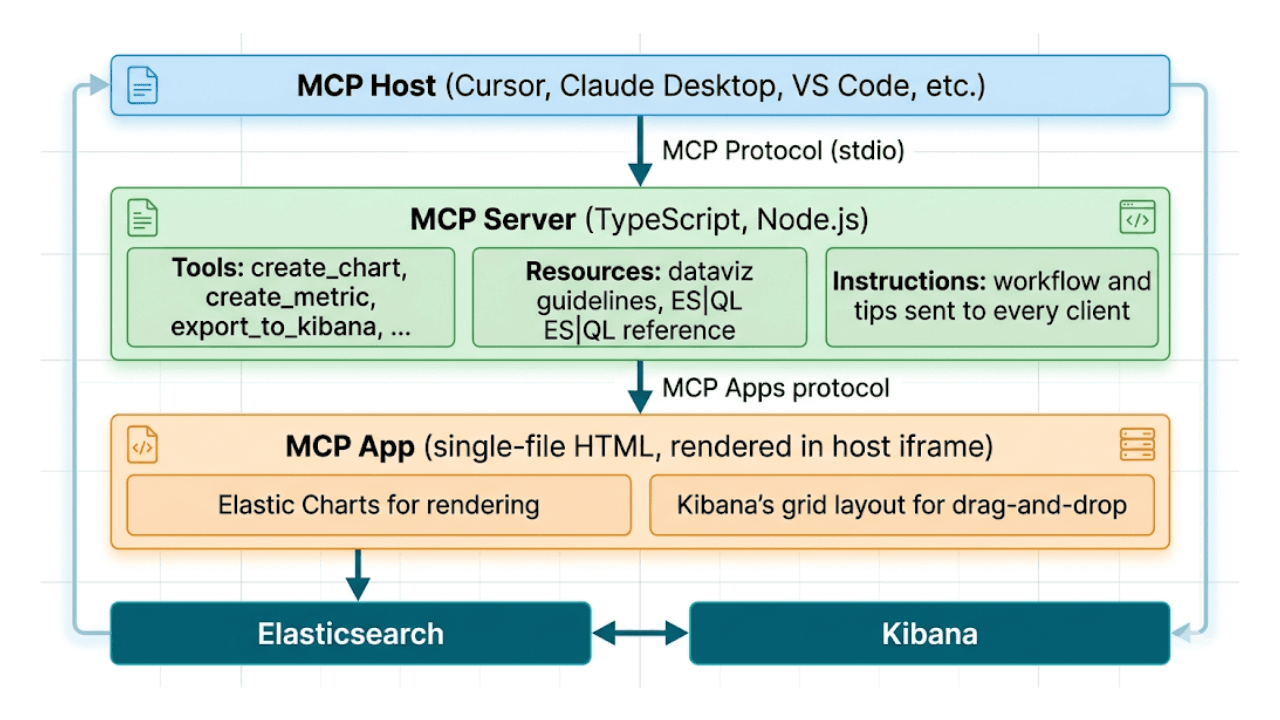
Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.