Hoje estamos lançando o jina-embeddings-v3, o primeiro modelo de base de busca Jina disponível no Gemini Enterprise Agent Platform Model Garden como um modelo de parceiro autoimplantável. A autoimplantação significa que o modelo é executado em instâncias de GPU dentro do seu projeto do Google Cloud e da sua Virtual Private Cloud (VPC). Sem chamadas de API externas, sem medição por token, sem limites de taxa.
Com essa integração, os usuários do Elasticsearch ganham uma nova opção de implantação que mantém os dados dentro do perímetro de segurança, entrega custos de infraestrutura previsíveis e roda de forma nativa no Google Cloud. Ao mesmo tempo, o ecossistema mais amplo do Google Cloud ganha acesso aos modelos de busca e recuperação de última geração desenvolvidos especificamente pelo Jina.
Esta é a primeira etapa de uma implementação mais ampla. Junto com os modelos que virão a seguir, a linha formará uma pilha completa de recuperação: incorpore seus dados, incorpore consultas, recupere e reclassifique candidatos, e estenda a busca para imagens com embeddings multimodais, tudo na infraestrutura que você controla. Você pode começar hoje com jina-embeddings-v3, o modelo que já alimenta pipelines de busca em produção em todo o ecossistema Elasticsearch via Elastic Inference Service (EIS).
| Modelo | Tipo | Parâmetros | Principal recurso | Status do Model Garden |
|---|---|---|---|---|
| `jina-embeddings-v3` | Embedding de texto | 572 milhões | Ferramenta multilíngue comprovada, contexto 8K, saída de 1024 dimensões, truncável para 32 | Disponível agora |
| `jina-embeddings-v5-text-small` | Embedding de texto | 677M | Multilíngue sub-1B de última geração, contexto de 32K, saída de 1024 dimensões, truncável para 32 | Em breve |
| `jina-embeddings-v5-text-nano` | Embedding de texto | 239 milhões | O melhor da categoria com menos de 500 milhões de parâmetros, contexto de 8K, saída de 768 dimensões, truncável até 32 | Em breve |
| `jina-reranker-v3` | Reclassificador | 600 milhões | Reclassificador listwise, contexto de 131 mil, até 64 documentos | Em breve |
| `jina-clip-v2` | Embedding multimodal | 900M | Texto e imagem em espaço compartilhado, 89 idiomas e contexto de texto de 8K, imagens 512 × 512 | Em breve |
Cada modelo roda em uma única placa NVIDIA L4 (24 GB), a camada de GPU mais econômica do Google Cloud. A maioria dos outros modelos de incorporação no Google Cloud Model Garden exige um A100 de 80 GB ou H100, aproximadamente três vezes o custo da instância por hora antes mesmo de você começar a contar os tokens.
Não é necessária licença comercial adicional quando implantada via Vertex AI.
Por que o Model Garden?
Por que implantar pelo Model Garden em vez de usar uma API? Tudo se resume a três coisas: controle, custo e contexto.
Seus dados nunca saem do ambiente seguro
O principal atrativo para a maioria dos desenvolvedores é a arquitetura de autoimplantação. Quando você implanta um modelo Jina pelo Model Garden, os pesos são executados em instâncias de GPU dentro do seu próprio projeto Google Cloud e da sua própria VPC. Isso é um divisor de águas para qualquer pessoa que trabalhe em setores com preocupações com segurança de dados, como finanças ou saúde. Como não há chamadas externas de API, seus dados sensíveis permanecem dentro do seu perímetro de segurança.
Redimensionamento com previsão
Em vez de pagar toda vez que você incorpora uma frase ou reclassifica um documento, você paga um custo fixo por hora de instância. E como todo modelo Jina pode rodar em uma única NVIDIA L4, a camada de GPU mais acessível do Google Cloud, a barreira de entrada é baixa. Seja processando mil solicitações ou um bilhão, sua conta de infraestrutura permanece previsível. Essa é uma configuração que realmente recompensa você por aumentar seu tráfego, em vez de te taxar por isso.
Tudo sob o mesmo teto
Se seus dados já estão no Elasticsearch na Google Cloud, BigQuery ou Cloud Storage, faz sentido manter seus mecanismos de inferência próximos. Ao serem implementados por meio do Model Garden, os modelos da base de pesquisa Jina herdam todos os recursos corporativos que você já utiliza: gerenciamento de identidade e acesso (IAM) para controle de acesso, faturamento unificado na fatura existente do Google Cloud e a capacidade de integração com o Vertex AI Pipelines para fluxos de trabalho de operações de aprendizado de máquina (MLOps).
Embora a API Jina AI Cloud e o Elastic Cloud ofereçam o caminho mais rápido para picos de tráfego ou fluxos de trabalho de busca existentes, o Model Garden é ideal para aplicações corporativas que exigem segurança de dados rigorosa e custos previsíveis em grande escala. A Elastic quer encontrar você onde você estiver.
Modelos Jina AI
jina-embeddings-v3
Nosso modelo comprovado de embedding multilíngue com 572 milhões de parâmetros e contexto de token 8K. Pontuação 65,5 no Massive Text Embedding Benchmark (MTEB) em inglês. Compatível com cinco adaptadores LoRA (Low-Rank Adaptation) específicos para tarefas (consulta/passagem de recuperação, correspondência de texto, classificação, agrupamento) e truncamento Matryoshka de 1024 para 64 dimensões. Já amplamente adotado em todo o ecossistema Elasticsearch via EIS.
Estamos priorizando a v3 porque muitos sistemas de produção já dependem dela. Se você está migrando um pipeline baseado em v3 para o Google Cloud, agora pode executar o mesmo modelo de forma nativa sem alterar as dimensões de embedding nem reindexar.
jina-embeddings-v5-text (pequeno e nano)
Nossos modelos de incorporação de texto de quinta geração, lançados em fevereiro de 2026, alcançam desempenho de alto nível, competindo com modelos muitas vezes maiores.
v5-text-small (677 milhões) pontua 67,0 no conjunto de benchmarks Multilingual MTEB (MMTEB), abrangendo 131 tarefas de nove tipos, e 71,7 no benchmark MTEB em inglês. É o modelo de incorporação multilíngue sub-1B mais forte no MTEB Leaderboard.
v5-text-nano (239 milhões) tem 65,5 pontos no MMTEB. Nenhum outro modelo com menos de 500 milhões de parâmetros atinge esse nível. Com menos da metade do tamanho da maioria dos modelos comparáveis, é a escolha natural para implantações sensíveis à latência.
Ambos os modelos oferecem suporte:
- Quatro adaptadores LoRA específicos para tarefas: recuperação, correspondência de texto, classificação e clustering. Selecionar um adaptador apropriado por meio do parâmetro
taskno momento da inferência. - Truncamento da dimensão matrioshka: reduza as dimensões de embedding de 1024 (ou 768 para nano) para 32. A perda de qualidade é mínima em truncamento moderado (por exemplo, 256 dimensões). Ao reduzir as dimensões pela metade, você reduz o armazenamento pela metade.
- Quantização binária: comprima embeddings de 1024 dimensões de 2KB para 128 bytes com binarização. O treinamento especial faz com que esta compressão tenha perdas mínimas.
- Multilíngue: 119 idiomas (pequeno) e 93 (nano).
jina-reranker-v3
Um reclassificador de listas multilíngue com 0,6 bilhões de parâmetros, construído usando uma arquitetura de interação última, mas não tardia. A consulta e até 64 correspondências de candidatos são inseridas em uma única janela de contexto de 131 mil tokens, e o modelo realiza uma comparação cruzada de documentos antes da pontuação. O Jina Reranker v3 alcança 61,94 nDCG@10 no BEIR, superando o modelo por ser 6× menor em tamanho. Isso é fundamentalmente diferente dos reclassificadores pontuais, que pontuam cada documento isoladamente, produzindo melhores resultados, especialmente para recuperação de trechos a partir de documentos isolados.
jina-clip-v2
Um modelo de incorporação multimodal e multilíngue de 0,9B que mapeia texto e imagens em um espaço compartilhado de 1024 dimensões. Ele é compatível com:
- 89 idiomas para recuperação de texto-imagem.
- Resolução de imagem 512×512.
- Entrada de texto com token de 8 mil.
- Truncamento de Matryoshka de 1024 para 64 dimensões para ambas as modalidades.
Altamente competitivo em benchmarks de imagem para texto, incluindo tarefas multilíngues.
Para começar
Jina Embeddings v3 está disponível no Model Garden hoje. Veja como fazê-lo funcionar.
Você precisa de um projeto do Google Cloud com a API Vertex AI habilitada e cota de GPU suficiente para pelo menos uma instância g2-standard-8 (NVIDIA L4). Se você é novo no Google Cloud, comece pelo guia de configuração.
A página Model Garden para Jina Embeddings v3 guia você pelo fluxo completo: faça upload do modelo, crie um endpoint, escolha o tipo de máquina e implante. Abra-o em seu próprio projeto e siga as etapas guiadas. Máquinas A100 e H100 também estão disponíveis onde a região e a cota permitem, mas L4 é tudo que você precisa para começar.
Desde o clique até a primeira incorporação, todo o processo leva alguns minutos.
O que vem depois
Jina Embeddings v3 é o ponto de partida. Nas próximas semanas, traremos o restante do stack de recuperação Jina para o Model Garden: embeddings de texto v5 (pequeno e nano), jina-reranker-v3 e jina-clip-v2 para busca multimodal. Tudo será executado em uma única GPU L4 com o mesmo modelo de autoimplantação.
Conteúdo relacionado

11 de maio de 2026
Um índice, todas as mídias: Apresentando jina-embeddings-v5-omni
O jina-embeddings-v5-omni permite incorporar texto, imagens, vídeos e áudio em um único índice do Elasticsearch e realizar consultas em todos eles simultaneamente.

23 de fevereiro de 2026
jina-embeddings-v5-text: Incorporações de texto compactas e de última geração para busca e aplicações inteligentes
Apresentação dos modelos jina-embeddings-v5-text models, including jina-embeddings-v5-text-small e jina-embeddings-v5-text-nano explicando como usar esses modelos de incorporação multilíngue por meio do Elastic Inference Service (EIS).
1 de janeiro de 2026
Uma introdução aos modelos Jina, sua funcionalidade e seus usos no Elasticsearch
Confira os embeddings multimodais Jina, o Reranker v3 e os modelos semânticos de embedding, além de como usá-los nativamente no Elasticsearch.

22 de maio de 2026
Kibana reduz o tempo de carregamento do dashboard em até 25% — aqui está a estratégia de sondagem por trás disso
Descubra como o Kibana usa sondagem contínua e detecção de HTTP/2 no navegador para reduzir o tempo de carregamento do dashboard em até 25%, com recurso automático ao HTTP/1.
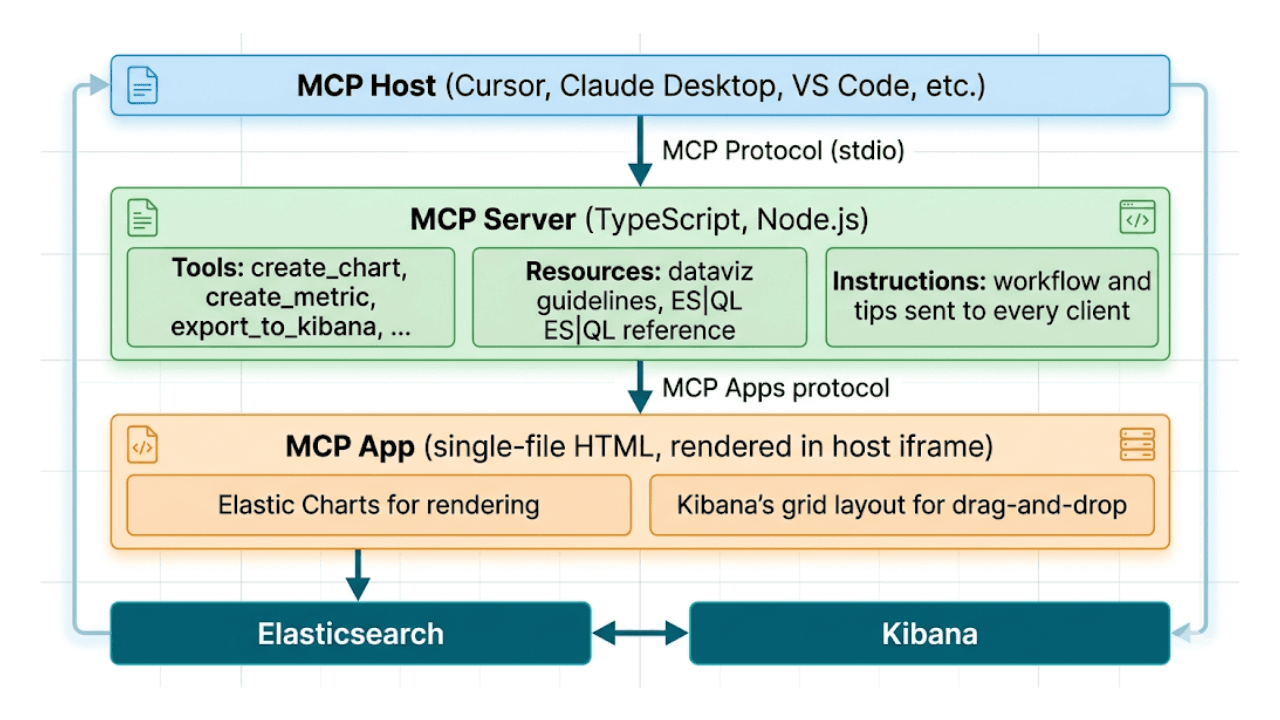
Descreva, não desenhe: dashboards nativos de IA do Kibana via MCP e ES|QL
Do prompt ao dashboard. Aprenda a construir dashboards do Kibana com linguagem natural, usando example-mcp-dashbuilder: uma aplicação MCP open source que escreve consultas ES|QL, cria gráficos interativos e exporta dashboards totalmente funcionais diretamente para Kibana.